NVIDIA 张量核心的演进:从 Volta 到 BlackwellAmdahl 定律、强扩展、异步执行、Blackwell、Hopper、Ampere、Turing、Volta、TMA

本文信息来源:semianalysis
作者:Dylan Patel 和 Kimbo Chen
在我们去年底发布的 《AI 扩展定律》文章中,我们讨论了多种 AI 扩展定律如何持续推动 AI 行业向前发展,使模型能力实现了超越摩尔定律的增长,同时单位 Token 成本也迅速下降。这些扩展定律由训练和推理的优化与创新推动,但超越摩尔定律的计算能力进步同样发挥了关键作用。
在这方面,在《AI Scaling Laws》一文中,我们重新审视了关于算力扩展的数十年争论,回顾了 2000 年代末 Dennard Scaling 的终结,以及 2010 年代末经典摩尔定律下每晶体管成本下降速度的终结。尽管如此,算力能力依然以极快的速度持续提升,接力棒已经交给了其他技术,比如先进封装 、3D 堆叠 、 新型晶体管以及像 GPU 这样的专用架构。

在 AI 和深度学习领域,GPU 的算力提升速度超过了摩尔定律的步伐,年复一年持续带来令人瞩目的“ 黄氏定律 ”性能提升。推动这一进步的核心技术正是 Tensor Core。
尽管 Tensor Core 无疑是现代 AI 和机器学习基础的基石,但即使是许多该领域经验丰富的从业者,对其了解也并不深入。GPU 架构及其上运行的编程模型的快速演进,使得机器学习研究人员和科学家越来越难以跟上 Tensor Core 的最新变化,并理解这些变化所带来的影响。

在本报告中,我们将介绍主要数据中心 GPU 的核心特性,首先解释性能工程的重要基本原理。随后,我们将梳理 Nvidia Tensor Core 架构及其编程模型的演变过程,重点阐述这一演变背后的动因。我们的最终目标是为理解 Nvidia GPU 架构提供参考资源,并对其架构演进提供直观见解。只有在解释完每一代架构后,我们才能讲述 Blackwell Tensor Core 的精妙之处及其全新的内存层级结构。
我们需要说明的是,深入理解计算机体系结构是理解本文许多解释和讨论的前提条件,本文将仅提供一小节 CUDA 编程内容作为复习,而不会讲解 GPU 体系结构的基础概念。我们将以 Tensor Core 领域的前沿知识为基础,通过详细的解释,将目前属于“部落知识”的内容整理为易于理解、结构化的见解,从而扩展对这一前沿技术的理解。
正如大学会开设 101 课程和 4000 级课程一样,SemiAnalysis 上的不同文章将针对不同层次的理解,以及来自不同职业和专业背景的读者。
我们要感谢我们的合作伙伴:
- Jay Shah,Colfax Research:出色的 CUTLASS 教程以及多次会议,细致核查技术细节
- Ben Spector,斯坦福 Hazy Research:对编程模型的变革和写作建议提供了极具价值的见解
- Tri Dao,普林斯顿大学与 Together AI:审阅了草稿并给出了详细反馈
- Neil Movva,Together AI:审阅了草稿并就 GPU 内核编写提供了见解
- Charles Frye,Modal:提供了教学用 GPU 术语表并对草稿进行了总体审阅
- Simon Guo,斯坦福大学博士生:绘制了封面图片并审阅了草稿
- NVIDIA:关于 Tensor Core 设计演进的共享背景。团队包括:
- Ian Buck,CUDA 的发明者
- Jonah Alben,GPU 架构与工程负责人
- 许多其他 GPU 大师
SemiAnalysis 将从下周开始在 Instagram Reels 和 TikTok 发布独家内容。关注我们的社交媒体,获取关于 AI 和 GPU 行业的最新见解。
性能第一性原理
阿姆达尔定律
对于固定的问题规模,Amdahl 定律规定了通过增加计算资源进行并行化所能获得的最大加速比。具体来说,扩展计算资源只能缩短并行部分的执行时间,因此性能提升受限于串行部分。用公式量化时,最大性能提升为:

其中 S 是并行工作执行时间,p 是可并行化工作的加速比。在理想情况下,如果并行部分能够完全并行化,加速比 p 可以等于处理单元的数量。
强扩展性与弱扩展性
强扩展性和弱扩展性描述了在不同问题设置下,计算资源扩展所带来的性能提升。强扩展性是指通过扩展计算资源来解决固定规模的问题,Amdahl 定律量化了强扩展性的加速比。另一方面,弱扩展性是指通过扩展计算资源,在相同时间内解决更大规模的问题。例如,使用 4 倍的计算资源,在相同时间内处理 4 倍大小的图像。我们推荐这篇博客文章以获取更详细的解释。

强扩展性和弱扩展性在不同问题规模下表现出不同的性能提升。强扩展性在所有问题规模下都能带来加速,而弱扩展性只在我们用更多计算资源解决更大问题时才保证性能提升。

数据移动是原罪
数据移动之所以被视为原罪,是因为在运行时间和扩展性方面,计算成本低廉,而数据移动成本高昂。数据移动本质上更慢,因为现代 DRAM 单元的操作速度为几十纳秒,而晶体管的切换速度则在亚纳秒级。就扩展性而言,尽管自 2000 年代以来计算速度的提升已经放缓, 但内存速度的提升更为缓慢 ,从而形成了内存墙 。
张量核心架构演进
张量核心代际概览
在本节中,我们将介绍主要采用 Tensor Core 的 Nvidia GPU 架构,包括 Tesla V100 GPU、A100 Tensor Core GPU、H100 Tensor Core GPU 以及 Blackwell GPU。我们还加入了一个 Tensor Core 出现前的部分,以便回顾 CUDA 编程模型。我们将简要介绍与理解 Tensor Core 相关的主要特性和变化,详细内容则留待各小节中链接的其他资料进一步说明。
张量核心之前
PTX 编程模型
并行线程执行(PTX)是一种虚拟指令集,可以跨 GPU 代际进行抽象。PTX 程序描述了一个内核函数 ,该函数由大量 GPU 线程执行,这些线程在 GPU 的硬件执行单元(即 CUDA 核心)上运行。 线程被组织为一个网格, 网格由多个协作线程数组(CTA)组成。PTX 线程可以访问多个状态空间的数据,这些状态空间是具有不同特性的内存存储区域。具体来说,线程拥有每线程独立的寄存器 ,同一个 CTA 内的线程共享共享内存 ,所有线程都可以访问全局内存 。更多信息请参阅 CUDA 文档的本节 。

PTX 机器模型
GPU 架构围绕着一组流式多处理器(SM)构建。一个 SM 包含标量处理核心、多线程指令单元和片上共享内存。SM 将每个线程映射到一个标量处理核心(也称为 CUDA 核心),多线程指令单元以 32 个并行线程为一组(称为 warp)来管理线程。
在指令发射时,指令单元选择一个 warp,并向该 warp 的线程发出一条指令。这种执行方式称为单指令多线程(SIMT)。与单指令多数据(SIMD)类似,SIMT 用一条指令控制多个处理单元,但与 SIMD 不同的是,SIMT 指定的是单个线程的行为,而不是向量宽度。更多信息请参阅 CUDA 文档的本节 。

流式汇编器
流式汇编器(SASS)是 PTX 所虚拟化的特定架构指令集。更多信息请参见 CUDA 二进制工具文档 。遗憾的是,由于 NVIDIA 对其架构 ISA 细节进行保密,SASS 的相关文档并不完善。
Volta
为什么 NVIDIA 增加了 Tensor Core
随着深度学习的兴起,业界注意到机器学习工作负载需要硬件加速。2015 年初,Google 部署了 TPUv1 来加速其内部的机器学习工作负载,而在 2017 年,Nvidia 推出了专门用于矩阵运算的硬件。虽然 GPU 在发出指令时由于其简单的硬件流水线只消耗少量能量(约 30pJ),但像 HFMA 这样简单的浮点运算消耗的能量更少,仅为 1.5pJ。这导致指令所需的能耗比浮点运算本身高出 20 倍。因此,为矩阵乘法执行大量浮点运算在能耗上是低效的。为了摊薄指令的开销,我们需要使用能够每条指令完成更多计算的复杂指令。为此,Nvidia 设计了半精度矩阵乘加(HMMA)指令 ,这是一种专门用于执行半精度矩阵乘法的指令。 执行该指令的专用硬件是 Tensor Core,于 2017 年在 Volta 架构的 Tesla V100 GPU 中首次引入。Volta 的 Tensor Core 是在 Volta 架构开发的非常后期才加入的,仅在流片前的几个月内完成,这证明了 Nvidia 能够极其迅速地调整其架构。

MMA 指令概述
给定一个矩阵,乘加(MMA)指令计算 D = A * B + C:
- A 是一个 M 行 K 列的矩阵
- B 是一个 K 行 N 列的矩阵
- C 和 D 是 M 行 N 列的矩阵
我们用 mMnNkK 或 MxNxK 来表示矩阵的形状。
为了完成整个计算,首先我们将矩阵 A、B 和 C 从共享内存加载到线程寄存器中,使每个线程都持有矩阵的片段。其次,我们执行 MMA 指令,该指令从线程寄存器读取矩阵,在 Tensor Core 上进行计算,并将结果存储到线程寄存器。最后,我们将结果从线程寄存器存回共享内存。整个计算由多个线程协同完成,这意味着每一步都需要协作线程之间的同步。

第一代张量核心——Warp 范围的 MMA
一颗 Tesla V100 GPU 的一个 SM 包含 8 个张量核心,每两个为一组。每个张量核心每个周期能够完成等效于 4x4x4 矩阵乘法的计算,这相当于每个 SM 每周期可实现 1024 次浮点运算。

NVIDIA 设计了 PTX 指令 mma 以针对更底层的 HMMA 指令。在 Volta 架构上,一条 MMA 指令执行一次 8x8x4 的矩阵乘法,8 个线程组成的四元组共同参与操作,协同保存输入和输出矩阵。这里 T0 指的是线程 0,[T0, T1, T2, T3] 和 [T16, T17, T18, T19] 是线程组,这两个线程组组成一个四元组。

在数据类型方面,Volta Tensor Core 支持 FP16 输入并以 FP32 进行累加,这与 NVIDIA 的混合精度训练技术相对应。该技术表明,可以在较低精度下训练模型而不会损失模型精度。
要全面了解 MMA 布局,请参考 Citadel 的微基准测试论文,Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking。要了解 Volta Tensor Core MMA 的交错布局模式,请阅读幻灯片 Programming Tensor Cores: Native Tensor Cores with CUTLASS。最后,关于 Volta 架构的其他信息,请参阅白皮书 NVIDIA Tesla V100 GPU Architecture。
图灵
Turing 架构包括第二代 Tensor Core,这是对 Volta Tensor Core 的增强版本,增加了对 INT8 和 INT4 精度的支持。Turing Tensor Core 支持新的 warp 级同步 MMA,我们将在下一节讨论。Turing Tensor Core 还实现了深度学习超级采样(DLSS),标志着 NVIDIA 开始将深度学习应用于游戏图形。感兴趣的读者可以参考 NVIDIA 的博客文章 NVIDIA Turing Architecture In-Depth 和 Turing 架构白皮书 。
安培
异步数据拷贝
在 Ampere 架构中,NVIDIA 引入了异步数据拷贝,这是一种以异步方式将数据直接从全局内存复制到共享内存的方法。在 Volta 架构上,要将数据从全局内存加载到共享内存,线程必须先将数据从全局内存加载到寄存器,然后再存储到共享内存。然而,MMA 指令对寄存器的使用量很大,且必须与数据加载操作共享寄存器文件,导致寄存器压力过高,并且在寄存器文件中进出数据时浪费了内存带宽。
异步数据拷贝通过从全局内存(DRAM)获取数据并直接存储到共享内存(可选 L1 访问),缓解了这一问题,从而为 MMA 指令释放出更多寄存器。数据加载和计算可以异步进行,这在编程模型上更为复杂,但能够释放更高的性能。
该功能作为 PTX 指令线程级异步拷贝 cp.async 实现( 文档 )。对应的 SASS 指令为 LDGSTS,即全局内存到共享内存的异步拷贝。具体的同步方法包括 async-group 和基于 mbarrier 的完成机制,详细内容见此处 。

第三代 Tensor Core——线程束级同步 MMA
Ampere 每个 SM 拥有 4 个 Tensor Core,每个 Tensor Core 每个周期可执行 512 次 FLOPs,总计每个 SM 每周期可实现 2048 次稠密 FLOPs,性能是 Volta 的两倍。
Volta 需要由 8 个线程组成的四组线程参与一次 MMA 操作,而 Ampere 则需要完整的 32 线程 warp。将 MMA 指令扩展到整个 warp 简化了线程布局,并减少了 Ampere 的寄存器文件压力。例如,以下是形状为 16x8x16 的混合精度浮点数的线程和数据布局:

NVIDIA 在 Ampere 中引入了 ldmatrix,这是一种增强型的矢量化加载操作。与 mma 类似,ldmatrix 是 warp 级别的,这意味着一个 warp 内的线程协同加载一个矩阵。与发出多条加载指令相比,这减少了地址生成寄存器的使用,从而降低了寄存器压力。更多信息请参见 CUDA 文档。
ldmatrix 以与 Tensor Core 数据布局相匹配的方式将数据加载到寄存器中。与 Volta 的交错模式相比(参见 Programming Tensor Cores: Native Tensor Cores with CUTLASS),更简单的线程和数据布局极大地提升了编程的易用性。观看 GTC 演讲 Developing CUDA Kernels to Push Tensor Cores to the Absolute Limit on NVIDIA A100,了解更多关于 Ampere 的内存加载如何与 Tensor Core 保持一致的详细信息。
Ampere MMA 支持 Brain Floating Point Format(BF16),该格式已成为半精度数据类型的事实标准。BF16 提供与 FP32 相同的 8 位指数范围,但尾数为 7 位,实现了 FP32 级别的动态范围,同时存储成本减半。BF16 还消除了混合精度训练中对损失缩放的需求。
Hopper
线程块集群
随着 SM 数量的增加,单个 SM 与整个 GPU 之间的规模差异也在扩大。为了在 CTA(映射到 SM)与网格(映射到整个 GPU)之间提供更细粒度的控制,NVIDIA 在 Hopper 架构中新增了一个线程层级—— 线程块簇 ,它对应于物理上位于同一图形处理簇(GPC)中的一组 SM。线程块簇也被称为协作网格阵列(CGA),在 CUDA 文档中简称为 cluster( 更多信息请参见此处 )。
线程块簇(thread block cluster)中的 CTA 被保证会在同一 GPC 内的 SM 上协同调度,并默认每个 SM 分配一个 CTA。这些 SM 的共享内存分区组成了分布式共享内存(DSMEM)。线程可以通过专用的 SM 到 SM 网络以低延迟访问其他 SM 的共享内存(无需经过 L2 缓存)。通过将 GPC 硬件执行单元暴露给编程模型,程序员可以减少数据移动并提升数据局部性。

张量内存加速器
为了提高数据获取效率,NVIDIA 在每个 Hopper SM 上增加了张量内存加速器(TMA)。TMA 是一个专用硬件单元,用于加速全局内存与共享内存之间的大量异步数据传输(批量异步拷贝)。
CTA 中的单个线程可以发起 TMA 拷贝操作。TMA 释放了线程以执行其他独立工作,负责地址生成,并带来越界处理等额外优势。在 PTX 中,对应的指令是 cp.async.bulk,详细内容见 CUDA 文档的这一部分 。
然而,对于小型请求,TMA 加载的延迟高于常规异步数据拷贝,因为地址生成的开销较大。因此,NVIDIA 建议程序员在进行大规模数据拷贝时使用 TMA,以摊销这些开销。例如,在 LLM 推理中,TMA 并不适用于以小块加载 KV 缓存的工作负载,但当每个块是 16 字节的倍数时效果良好。关于这方面更具体的例子,请参见 SGLang 前缀缓存 、论文 FlashInfer 第 3.2.1 节、论文 Hardware-Efficient Attention for Fast Decoding 第 4.2 节,以及 ThunderKittens MLA 解码 。
TMA 还支持一种称为多播(multicast)的数据加载模式,在该模式下,TMA 会根据多播掩码(multicast mask)将全局内存中的数据加载到线程块集群中多个 SM 的共享内存中。与其为多个 SM 分别发起多次全局内存加载以加载相同的数据,不如通过多播一次性完成加载。具体来说,线程块集群中的多个 CTA 会将部分数据加载到各自对应的 SMEM 中,并通过 DSMEM 共享这些数据。这减少了 L2 缓存的流量,进而降低了 HBM 的流量。我们建议阅读 Jay Shah 的 TMA 教程 以获取更多详细信息。

第四代张量核心——Warpgroup 级异步 MMA
NVIDIA 在 Hopper 架构中引入了一种新型的 MMA,即 warpgroup 级 MMA(wgmma)。wgmma 是面向 warpgroup 的,这意味着由 4 个 warp 组成的 warpgroup 共同执行一次 MMA 操作。wgmma 支持更广泛的形状。例如,混合精度 MMA 支持 m64nNk16,其中 N 可以是 8 到 256 之间的 8 的倍数。wgmma.mma_async 会被转换为一组新的 SASS 指令:GMMA。另一个例子是,半精度 wgmma 指令会被转换为 HGMMA。关于 MMA 形状和数据类型的详细信息,请参见此 CUDA 文档部分 。
虽然一个 warpgroup 中的所有线程会在它们的寄存器中共同保存输出矩阵,但 Hopper Tensor Core 可以直接从共享内存加载操作数,而不是从寄存器加载,从而节省了寄存器空间和带宽。具体来说,操作数矩阵 A 可以驻留在寄存器或共享内存中,而操作数矩阵 B 只能通过共享内存访问。有关 wgmma 的完成机制、SMEM 布局等详细信息,请参见 CUDA 文档 wgmma 部分 。

对于 wgmma 数据类型,Hopper 引入了 8 位浮点数据类型(E4M3 和 E5M2),并采用 FP32 累加。实际上, 累加路径被实现为 22 位定点格式(13 位尾数加上符号位和指数位),与真正的 32 位累加相比,动态范围受到了限制。由于张量核心精度降低,每进行 N_c 次累加就必须在 CUDA 核心中进行一次,以防止训练精度受限。( 参见本文第 3.3.2 节 )。这种降低精度的累加提升了效率,但以牺牲精度为代价。
有关 Hopper 架构的更多信息,请参见以下内容:
- GTC 演讲: 深入解析 NVIDIA Hopper 架构
- NVIDIA 博客文章概述:NVIDIA Hopper 架构深度解析
- 白皮书:NVIDIA H100 Tensor Core GPU 架构
- 微基准测试: 对 Nvidia Hopper GPU 架构的基准测试与剖析
- 微基准测试: 通过微基准测试和多层次分析剖析 NVIDIA Hopper 架构
有关如何编程 Hopper GPU 的示例,请参见:
- GTC 演讲: 为 Hopper 架构优化应用程序
- CUTLASS 讲座: 在 Hopper Tensor Cores 上开发最优 CUDA 内核
- Colfax 博客文章:CUTLASS 教程:在 NVIDIA Hopper GPU 上使用 WGMMA 实现快速矩阵乘法
Blackwell
张量内存
极高的寄存器压力在 Hopper 架构上依然存在,这促使了 Tensor Memory(TMEM) 的诞生,这是一种专为 Tensor Core 操作设计的新型内存。在每个 SM 上,TMEM 拥有 128 行(通道)和 512 列 4 字节单元,总容量为 256 KB,这也正好是一个 SM 上寄存器文件的大小。
TMEM 具有受限的内存访问模式。具体来说,需要一个 warpgroup 才能访问整个 TMEM,并且 warpgroup 中的每个 warp 只能访问特定的一组通道。通过限制内存访问模式,硬件设计师可以减少访问端口的数量,从而节省芯片空间。另一方面,这种设计也意味着尾声操作需要由 warpgroup 来执行。与共享内存不同,程序员必须显式管理 TMEM,包括分配、释放以及在 TMEM 中复制数据进出。

CTA 对
如果线程块簇中的两个 CTA 的 CTA 序号仅在最后一位上不同,例如 0 和 1、4 和 5,则它们构成一个 CTA 对 。一个 CTA 对映射到一个纹理处理簇(TPC),TPC 由两个 SM 组成,并与其他 TPC 组合形成一个 GPC。当 Blackwell 张量核心以 CTA 对粒度执行操作时,这两个 CTA 能够共享输入操作数。这种共享减少了对 SMEM 容量和带宽的需求。
第五代张量核心 MMA
第五代 Tensor Core MMA 指令(PTX 中的 tcgen05.mma)已经完全不再使用寄存器来存放矩阵。操作数现在驻留在共享内存和 Tensor Memory 中。
具体来说,假设 MMA 计算 D = A * B + D:不使用线程寄存器可以消除复杂的数据布局,并释放线程寄存器空间用于其他工作,如尾部操作。与 wgmma 使用 warpgroup 发起 MMA 操作不同,tcgen05.mma 具有单线程语义,这意味着单个线程即可发起 MMA 操作。这消除了 warp 在发起 MMA 时的作用。

一个值得注意的 MMA 变体是 MMA.2SM,它使用 2 个 SM 协同执行一次 MMA 操作。MMA.2SM 以 CTA 对为粒度执行操作,并且由于 tcgen05.mma 具有单线程语义,CTA 对中主导 CTA 的单个线程发起 MMA.2SM。这里我们展示了数据路径组织布局 A。布局 A 显示,MMA.2SM 相比于 1SM 版本( 布局 D)将 M 维度加倍,因此两个 SM 加载不同的矩阵 A 和 D 切片。此外,MMA.2SM 将矩阵 B 分割,减少了一半的数据加载量。

矩阵 B 在两个 SM 之间共享,这意味着 B0 和 B1 这两个 tile 需要通过 DSMEM 进行通信。尽管 DSMEM 和 SMEM 之间存在带宽差异,但由于我们加载的是更小的 tile,因此对协调的影响很小。不过,我们推测在 Blackwell 架构中,TPC 内 SM 之间的通信带宽高于 DSMEM,因此 MMA.2SM 利用了这一点以实现更好的性能。
第五代 Tensor Core 除了可以进行通用矩阵乘法外,还能执行卷积运算。tcgen05.mma 支持带有收集缓冲区的权重常驻模式,该缓冲区会缓存矩阵 B 以便重复使用。更多信息请参考 CUDA 文档以及相应的权重常驻 MMA 指令 。
在支持的数据类型方面,Blackwell 支持微缩浮点格式(MXFP),包括 MXFP8、MXFP6 和 MXFP4。详情请参见这篇论文 。Blackwell 还支持 NVIDIA 自有的 NVFP4 格式,该格式以比 MXFP4 更高的精度著称。这很可能是因为其更小的块大小、不同的缩放因子数据格式以及两级量化方法(参见这个 GitHub 问题 )。有关数据格式的对比,请参见这篇论文 。
在 Blackwell 架构中,由于 FP8 和 FP6 具有相同的理论吞吐量,我们认为它们在 Tensor Core 中共享物理电路。相比之下,CDNA4 的 FP6 吞吐量是 FP8 的两倍,因为其 FP6 单元与 FP4 共享数据通路。我们认为 UDNA 将会改为让 FP6 单元与 FP8 共享。
附注:结构化稀疏
Ampere 引入了 2:4 结构化稀疏性,理论上使 Tensor Core 的吞吐量翻倍。其实现方式是对权重矩阵进行剪枝,每 4 个元素中有 2 个为零。在这种格式下,矩阵通过移除零元素进行压缩,额外的元数据索引矩阵记录它们的位置,从而大致将内存使用和带宽减半。
根据这篇由中国工程师撰写的微基准测试论文 ,Ampere 的结构化稀疏性在指令级别上可以实现大规模 MMA 操作的 2 倍加速。论文还显示,在 Hopper 架构中,结构化稀疏性的 wgmma 指令能够实现 2 倍加速,并且在加载权重时最多可节省 2 倍的内存带宽。
不幸的是,2:4 结构化稀疏 GEMM 内核在 Hopper 上与其稠密对应内核相比,无法实现接近 2 倍的加速。这是由于在保持模型精度的同时进行结构化剪枝存在困难、cuSPARSELt 内核未经过优化以及 TDP 限制所致。除了中国的 AI 实验室和少量西方实验性研究论文外,大多数 AI 实验室在生产推理中忽略了 2:4 结构化稀疏性,而是专注于量化和蒸馏。Meta 正在 Llama 中进行相关实验,但在许多情况下,这也是一条死胡同。
此外,目前还没有封闭或开源模型能够在保持零精度损失的情况下,通过 2:4 FP8 结构化稀疏或 4:8 FP4 结构化稀疏实现性能提升,同时在结构化剪枝方面也普遍缺乏资源投入。我们建议,除非 NVIDIA 能够持续展示 SOTA 开源模型在推理中能够利用结构化剪枝,否则应当停止在主题演讲和市场宣传材料中使用 Jensen math 结构化稀疏 FLOPS。一个良好的第一步是对 DeepSeek 进行结构化稀疏,并展示其性能能够与蒸馏和 NVFP4 等量化等其他技术叠加提升。

在其第五代 Tensor Core 中,NVIDIA 为 NVFP4 数据类型引入了成对 4:8 结构化稀疏性。在这种方案中,每八个元素被分为四个连续的对,其中恰好有两对必须包含非零值,而其余两对则被裁剪为零。由于 NVFP4 是一种亚字节数据类型,我们认为这一限制促使 NVIDIA 采用了成对 4:8 的模式。尽管 4:8 稀疏性看起来比早期的 2:4 模式更为宽松,但由于增加了成对的要求,对于希望在裁剪时保持模型精度的机器学习工程师来说,这实际上并不是一个更宽松的约束。

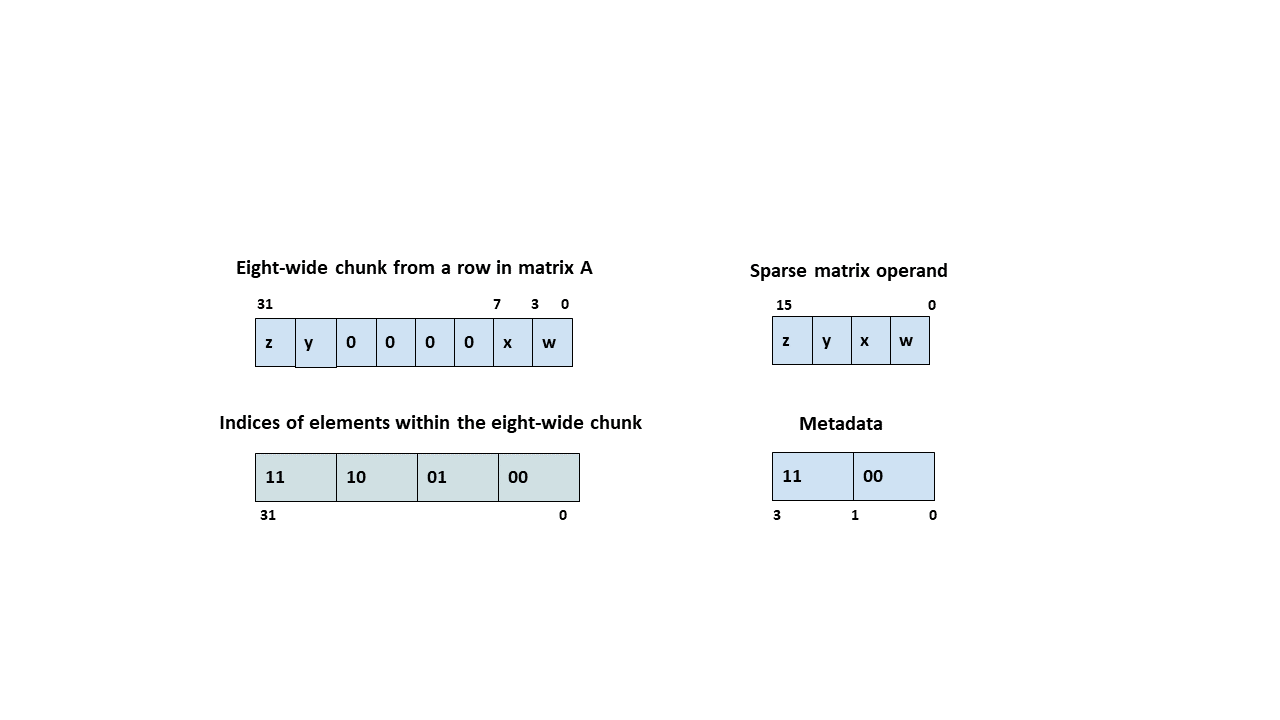{kind=link}
张量核心尺寸的增加

在各代产品中,NVIDIA 对张量核心尺寸的扩展比张量核心数量更为激进。NVIDIA 之所以选择扩展张量核心的尺寸而不是数量,是因为这更适合矩阵乘法的性能特性。具体来说,当问题规模扩大时,矩阵乘法的计算量呈立方增长,而数据移动量呈平方增长,这意味着算术强度呈线性增长。O(n)的算术强度,加上数据移动比计算更昂贵的事实,促使了张量核心尺寸的增加。

然而,无论是扩大核心规模还是增加核心数量,都需要付出量化效应的代价。具体来说,拥有大量核心会受到 tile 量化效应的影响,而增大核心规模则会导致 wave 量化效应 。wave 量化效应发生在工作单元数量不能被工作者数量整除时,导致在处理最后一批较小的工作时利用率下降。增加张量核心规模本质上是增加工作单元的大小,这会导致在处理小型矩阵时利用率较低(参见这篇 ThunderKittens 博客文章 )。

算术强度的线性增长同样推动了 MMA 形状的增大。更大的 MMA 形状提升了操作数共享的粒度。具体来说,发射更少但更大的 tile 可以增加数据重用,节省寄存器文件(RF)和共享内存(SMEM)的内存占用和带宽。在 Blackwell 之前的架构中,这导致了参与共同执行一次 MMA 操作的线程数量不断增加,从 Volta 的 8 线程四元组,到 Ampere 的 32 线程 warp,再到 Hopper 的 128 线程 warpgroup。
内存容量增加

几乎每一代的共享内存都在增加,而寄存器文件的大小则保持不变。其原因在于,Tensor Core 吞吐量的提升需要更深的分级缓冲区。
由于张量核心消耗数据的速度远快于全局内存的加载速度,我们使用中转内存对数据进行缓冲,这样内存加载就可以领先于 MMA 操作。 每一代张量核心的吞吐量都翻倍,但全局内存的加载延迟并没有降低,实际上还增加了。因此,我们需要增加中转内存的容量以缓冲更多数据。 为实现这一点,NVIDIA 选择将共享内存作为张量核心的中转内存,这也解释了为什么共享内存容量增加,而寄存器文件大小保持不变。
然而,Blackwell 的共享内存容量相比 Hopper 并没有增加。这是因为 tcgen05 MMA 可以利用 2 个 SM,因此每个 SM 的共享内存只需加载一半的操作数。这样一来,Blackwell 的共享内存容量实际上等于翻倍。
NVIDIA 对暂存内存的选择也解释了为什么操作数的位置逐渐从寄存器转移到共享内存。也就是说,NVIDIA 在 Blackwell 架构中增加了 TMEM,以支持提升的 Tensor Core 吞吐量。由于 TMEM 更靠近 Tensor Core,因此可以实现更高的能效。此外,单独设置一块内存还能提升总内存带宽,从而更好地满足 Tensor Core 的带宽需求。
在所有操作数中,矩阵 D 始终保留在 TMEM 中。我们可以利用 TMEM 的高能效优势,因为矩阵 D 的访问频率高于矩阵 A 和 B。例如,在朴素的分块矩阵乘法中,为了计算一个分块,矩阵 D 的分块会被访问 2Kt 次(Kt 次读取和 Kt 次写入,Kt 为 K 维度上的分块数量),而矩阵 A 和矩阵 B 的分块只需各访问一次。

MMA 指令的异步性

UTCHMMA、HGMMA、HMMA 中的“H”代表半精度,因为它是 16 位格式;而 QGMMA、UTCQMMA 中的“Q”代表四分之一精度(8 位),因为 8 位是全精度(32 位)的四分之一。“O”代表“Octal”(八分之一),意味着 32 位的八分之一,因为 UTCOMMA 是 FP4。
MMA 指令看似是从同步直接跳到了异步。实际上,MMA 指令在 SASS 层面是逐步变为异步的,这是因为需要与 LDSM 指令重叠执行。
在 SASS 级别上,一次 MMA 操作包括执行一条 LDSM 指令,将矩阵块从共享内存加载到寄存器文件,然后执行两条 HMMA 指令以完成 MMA。在执行过程中,这两条 HMMA 指令是异步发出的,并通过硬件互锁阻止寄存器的使用。由于硬件互锁不允许 LDSM 指令重叠执行,依次执行一条 LDSM 和两条 HMMA 指令会在指令发射流水线中产生一个小的空隙。然而,Tensor Core 的速度已经非常快,这个空隙会导致不可忽视的性能损失,因此需要为 MMA 引入异步完成机制。
Hopper 支持用于 wgmma 的异步完成机制 commit 和 fence。当发出 HGMMA 指令时,没有硬件互锁来保护寄存器的使用。相反,编译器会为下一个 MMA 调度 LDSM,并使用 FENCE 指令让下一个 HGMMA 等待。在 Blackwell 中,MMA 操作是完全异步的。用于加载到 Tensor Memory 的指令(tcgen05.ld / tcgen05.st / tcgen05.cp)全部都是显式异步的。

数据类型精度降低

在每一代 NVIDIA Tensor Core 的演进过程中,NVIDIA 不断加入更低精度的数据类型,从 16 位扩展到 4 位。这是因为深度学习工作负载对低精度极为宽容。对于推理任务尤其如此,其所需的精度甚至可以低于训练阶段。低精度不仅能提高能效,还能减少芯片面积占用,并实现更高的计算吞吐量。在新一代产品中,我们还看到 NVIDIA 移除了对 FP64 的支持,以便在芯片面积和功耗预算下优先支持低精度数据类型。
有趣的是,这种优先级的调整也影响了整数数据类型的支持。从 Hopper 开始,INT4 数据类型被弃用,而在 Blackwell Ultra 上,我们看到 INT8 的计算吞吐量也有所降低。这是由于低精度整数数据类型流行的时间被推迟所致。尽管 Turing 支持 INT8 和 INT4,但直到四年后,新的推理量化方法才真正利用 INT4 的紧凑性来服务 LLMs。那时,NVIDIA 已经在 Hopper 上弃用了 INT4 wgmma。
接下来,我们将讨论编程模型是如何演变的,包括从高占用率到单占用率的转变、显式异步执行的增加,以及这些设计如何与 NVIDIA 对强扩展性的押注相关联。
其他资源
如果读者想了解 CUDA 编程模型、硬件和相关概念的基础知识,Modal 的 GPU 术语表是一个涵盖 Blackwell 之前所有内容的极佳资源。要理解 CUDA 的核心思想,我们推荐 Stephen Jones 在 GTC 的所有演讲( 播放列表在这里 )。想要更深入了解内存特性,可以参考 GTC 演讲 CUDA 技术:最大化内存带宽与隐藏延迟 ,该演讲详细讲解了 Volta、Ampere 和 Hopper 的内存特性;而 CUDA 中的高级性能优化则深入探讨了内存模型。最后,关于 Blackwell 的专属资源,我们推荐 GTC 演讲使用 CUTLASS 编程 Blackwell Tensor Core、Colfax 关于 CUTLASS 的研究文章( 最新文章在这里 ),以及 CUTLASS 内核示例。