2025 年中期 LLM 市场更新:基础模型格局与经济学
本文信息来源:menlovc
随着使用量和支出激增,一位新的企业 LLM 领导者已经崛起。
**基础模型不仅仅在推动生成式 AI。它们正在塑造计算的未来。**随着其能力和经济性的演进,构建在其之上的系统、应用程序和行业也将随之发展。
当我们在去年 11 月发布了 Menlo Ventures 的 《2024 年:企业生成式 AI 现状》 报告时,关于这一基础层面的几个关键问题仍未得到解答:
- 对 LLM API 的需求是否能跟上消费者应用增长的步伐?
- 这些模型会变得多智能,它们达到那种程度的速度会有多快?
- 开源模型是否会在性能上追赶上闭源前沿模型,如果是这样,这将如何影响企业采用?
- 最重要的是,长期价值可能会在哪里积累?
六个月后,数据讲述了一个更清晰的故事:
在这个短暂的时期内,模型 API 支出已经翻了一番多——从 35 亿美元 (我们去年估计的总计 138 亿美元生成式 AI 支出中的一部分)跃升至 84 亿美元 。1 企业正在增加生产推理而不仅仅是模型开发,这标志着与往年的转变。
代码生成已成为 AI 的第一个突破性应用场景。除了预训练之外,基础模型现在正沿着第二个轴向扩展:通过验证器进行强化学习。虽然开源继续进步,但西方实验室在前沿突破方面的放缓缓解了此前企业采用率上升的趋势。因此,企业资金现在正集中于少数几个高性能的闭源模型,这为我们带来了新的市场领导者 Anthropic*。
为了了解当前 LLM 市场的状况,我们对 150 多位技术负责人 2 进行了调研,涵盖初创公司和企业,关注现代 AI 技术栈的基础层:谁在获得市场份额,什么在生产环境中运行,以及影响整个技术栈的选择标准。
我们了解到的情况如下:

Anthropic 在企业使用中超越 OpenAI
到 2023 年底,OpenAI 占据了企业 LLM 市场 50% 的份额,但其早期领先优势已经被侵蚀。如今,它仅占企业使用量的 25%3,仅为两年前持有份额的一半。
Anthropic 现在是企业 AI 市场的新领头羊,占据 32% 的份额,领先于 OpenAI 和 Google(20%),后者在最近几个月表现出强劲增长。Meta 的 Llama 持有 9% 的份额,而 DeepSeek 尽管在年初高调发布,但仅占 1%。

推动 Anthropic 登上 LLM 排行榜榜首的势头真正始于 2024 年 6 月 Claude Sonnet 3.5 的发布。随着 2025 年 2 月 Claude Sonnet 3.7 的发布,这一势头进一步加速,该版本首次展现了智能体优先 LLM 的真正面貌。到 2025 年 5 月,Claude Sonnet 4、Opus 4 和 Claude Code 进一步巩固了 Anthropic 的领先地位。
三个行业定义性趋势推动了 Anthropic 的发展势头:
- 代码生成成为了人工智能的第一个杀手级应用 。
Claude 迅速成为开发者代码生成的首选,占据了 42% 的市场份额,是 OpenAI(21%)的两倍多。仅仅一年时间,Claude 就帮助将一个单一产品的空间(GitHub Copilot)转变为一个价值 19 亿美元的生态系统。2024 年 6 月发布的 Claude Sonnet 3.5 展示了模型层面的突破如何推动应用市场的发展,使得全新的类别成为可能,如 AI 集成开发环境(Cursor、Windsurf)、应用构建器(Lovable、Bolt、Replit)和企业编码代理(Claude Code、All Hands)。 - **使用验证器的强化学习是扩展智能的新路径**。
在 2024 年,扩展智能的主要方式是通过预训练越来越大的模型和使用越来越多的数据。现在,互联网数据的规模正在成为一个速率限制因子。使用可验证奖励的强化学习(RLVR)进行后训练是推动边界的下一个突破。这种策略在编程等领域特别有效,因为编程更容易进行确定性验证。 - **将模型训练为使用工具的”智能体”使它们变得更加有用**。
LLMs 最初被设计为在单次回应中提供完整答案。然而,让它们能够逐步思考、推理问题并在多次交互中使用外部工具——创造出所谓的智能体——使它们在现实应用中变得更加有效。2025 年被称为”智能体之年”。Anthropic 在训练模型迭代改进回应并通过 MCP( 模型上下文协议 )集成搜索、计算器、编程环境和其他资源等工具方面引领潮流,显著提升了它们的能力和用户采用率。
企业中的开源采用趋于平缓
**13%**的 AI 工作负载目前使用开源模型,比六个月前的**19%**略有下降。4 市场领导者仍然是 Meta 广受欢迎的 Llama 模型,尽管 4 月发布的 Llama 4 在实际应用场景中表现不佳。
市场保持活跃,在过去六个月中, 字节跳动 Seed(豆包)、Minimax(Text 1)、 阿里巴巴 (Qwen 3)、 月之暗面 (Kimi K2)和智谱 AI(GLM 4.5)都有值得关注的发布,其中 DeepSeek(V3、R1)尤为突出。您可以在 OpenRouter*上通过一个 API 试用所有这些模型。
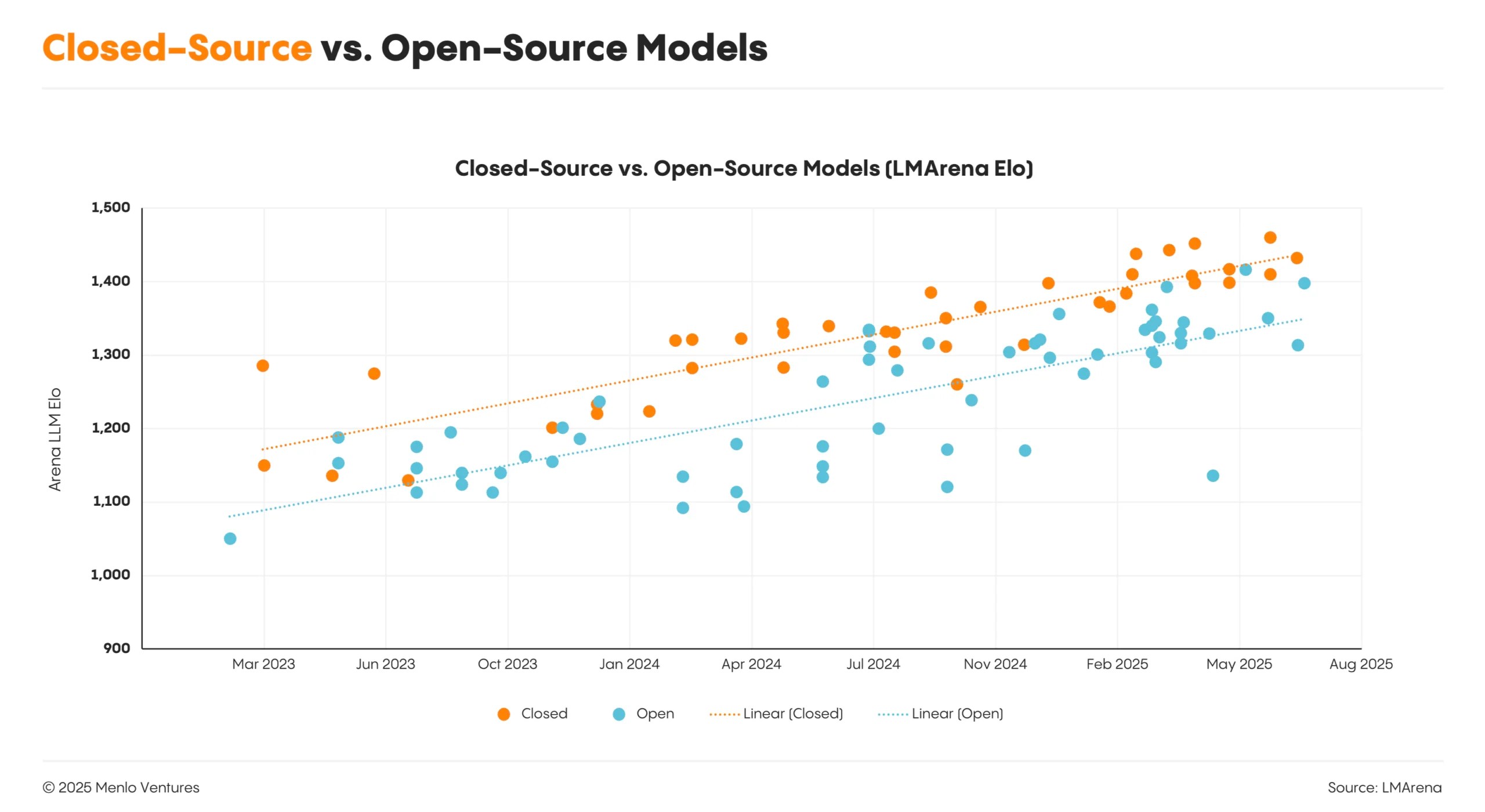
开源模型为企业提供了明显的优势:更大的定制化空间、潜在的成本节约,以及在私有云或本地环境中部署的能力。但尽管有这些优势和最近的改进,开源模型在性能上仍然落后于前沿的闭源模型9到12个月。
这种性能差距,加上部署开源模型的技术复杂性,以及企业不愿使用中国公司 API 的态度——而许多最近表现出色的开源模型都来自中国公司——导致了市场份额的停滞不前。
不仅仅是企业。出于这些原因,采用开源模型的初创公司也更少。正如一位受访者所说:
目前,我们 100%的生产工作负载都在运行闭源模型。我们最初在概念验证阶段使用 Llama 和 DeepSeek,但随着时间推移,它们无法跟上闭源模型的性能。

企业为性能而非价格更换模型
**在供应商之间切换相对容易,但越来越少见。**大多数团队会继续使用现有的供应商,只是在新模型可用时升级到最新版本。一旦开发者选定一个平台,他们往往会坚持使用,但会在发布更新、性能更高的模型时迅速升级。
根据我们的调研:**66%**的开发者在现有供应商内升级了模型,而**23%**的开发者在过去一年中完全没有更换模型。只有**11%**的开发者更换了供应商。
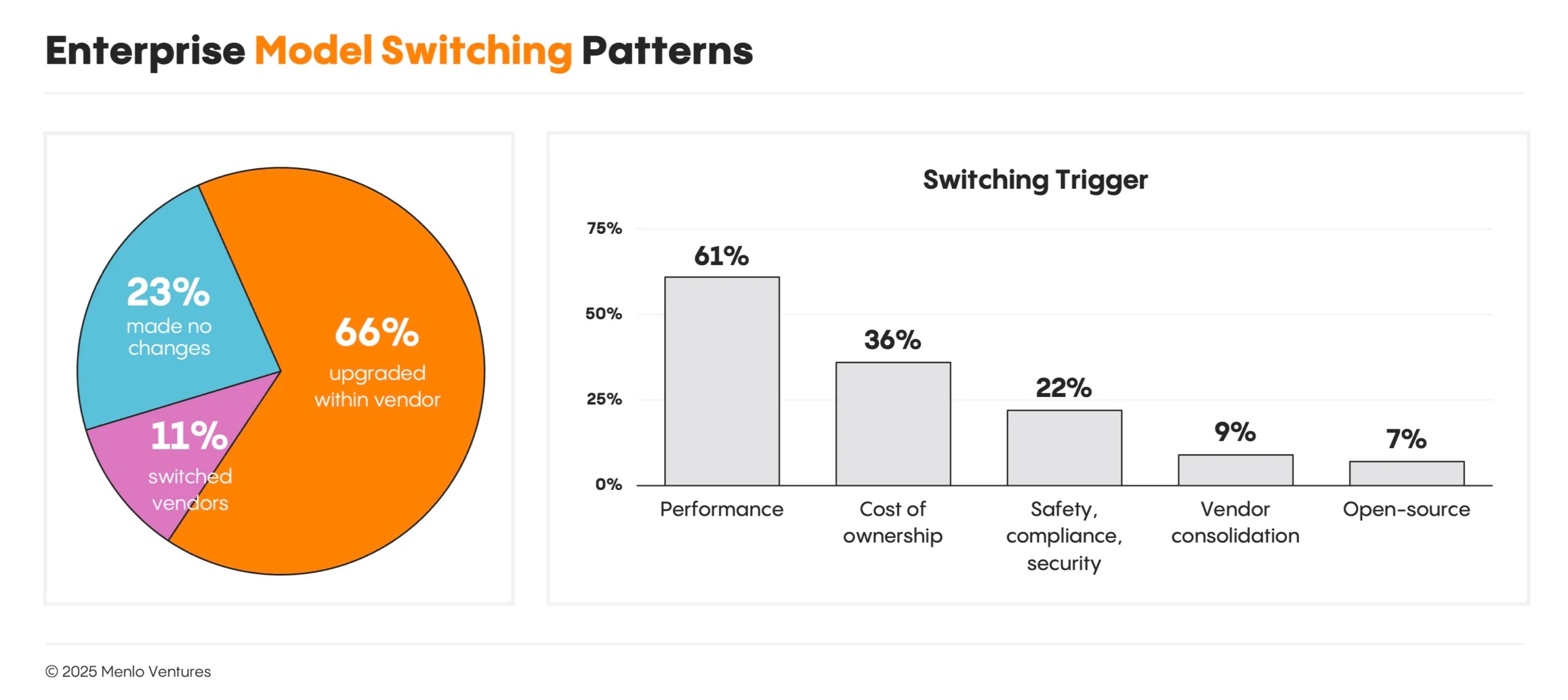
**性能驱动决策。** 构建者始终选择前沿模型,而非更便宜、更快的替代方案。他们优先考虑性能并愿意为此付费。当新模型发布时,切换会在数周内发生。例如,在 Claude 4 发布后的一个月内,Claude 4 Sonnet 就占据了 Anthropic 用户的**45%**份额,而 Sonnet 3.5 的份额从**83%**下降到**16%**。

这创造了一个意想不到的市场动态:即使个别模型价格下跌 10 倍 ,构建者也不会通过使用旧模型来获得节省;他们只是集体转向性能最佳的模型。

AI 支出正从训练转向推理
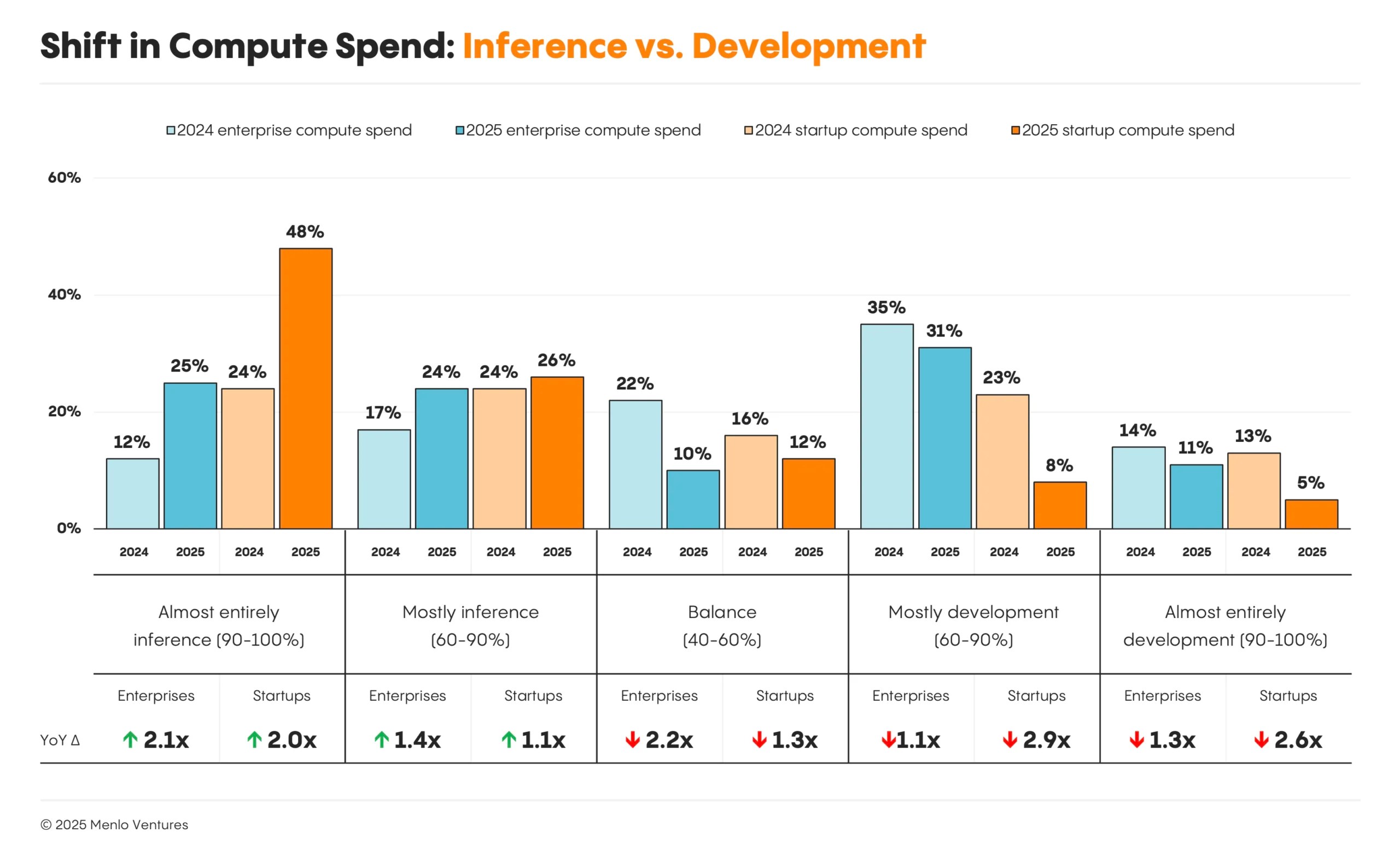
计算支出正在稳步从构建和训练模型转向推理,即模型在生产环境中的实际运行。这一转变在初创公司中最为明显:74% 的开发者现在表示他们的大部分工作负载是推理,比一年前的 48% 有所上升。大型企业也紧随其后。近一半(49%)的企业报告称,他们的大部分或几乎全部计算都是推理驱动的——比去年的 29% 有所增长。
未来发展方向
预测人工智能的未来可能是徒劳无功的。市场每周都在变化,不断有令人兴奋的新模型发布、基础模型能力的进步以及成本的大幅下降。不过,现在已经很清楚的是,条件已经成熟,可以在当今基础构建块之上构建新一代持久的 AI 业务。
在 Menlo Ventures,我们多年来一直在与构建 AI 基础设施层的创始人合作,包括 Anthropic、Cleanlab、Goodfire、Mercor、OpenRouter、Pinecone 和 Unstructured。如果您正在为 AI 时代创建基础设施、工具和应用程序,我们很乐意听到您的声音。
- 我们的 LLM 市场规模计算不包括前沿 AI 实验室从面向消费者的产品(如 ChatGPT)或企业应用(如 Claude for Work 和 Claude Code)获得的收入。在我们 2024 年 11 月的报告中,我们估计该市场的规模为 35 亿美元,而基础模型、模型训练、AI 基础设施和应用在生成式 AI 上的总支出为 138 亿美元。↩︎
- 本报告总结了对 150 名企业和初创公司技术决策者的调研数据,这些公司正在构建 AI 应用程序,调研时间为 2025 年 6 月 30 日至 7 月 10 日。企业定义为拥有 5,000 名或以上员工的组织。样本中包含的初创公司至少已获得 500 万美元的风险投资。基于这些基础数据,我们结合了作为该领域活跃投资者的观点和见解。↩︎
- LLM 市场份额反映的是生产环境 AI 使用量的比例,而非支出。调研受访者报告了他们的 AI 工作负载中使用各个模型的占比。回复根据每个企业和初创公司应用的规模进行了加权。↩︎
- 来源:Menlo Ventures 的 《2024 年:企业生成式 AI 现状》,2024 年 11 月 ↩︎





