如何使用 AI 筛选并丰富联系方式
你最优秀的销售代表早已知道谁值得联系。以下介绍如何提炼这种判断,将其文档化,并实现规模化运行。

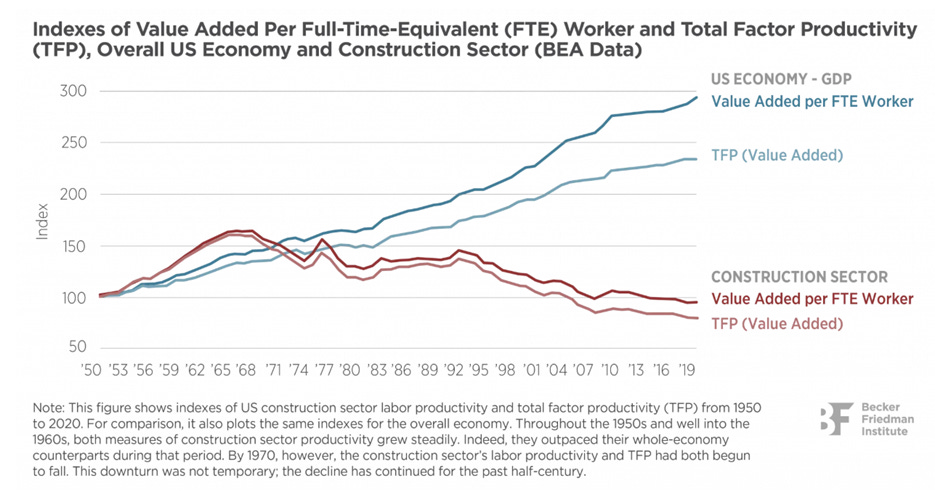
在一个账户内寻找联系人,是大多数 GTM 团队浪费大量时间的环节。而且这通常始于一个数据筛选条件。50 人公司的 “VP of Sales” 和 5,000 人公司的 “VP of Sales” 是完全不同的工作。同样的头衔,不同的世界。但大多数团队会对两者使用同样的筛选条件,给销售代表塞进那些原本就不可能转化的联系人,然后再疑惑为什么看不到结果。
这里真正发生的是:你在把判断外包给数据库。而数据库并不知道在你的公司里什么才算“好”——你才知道。
问题所在
大多数团队都把联系方式搜集当作一次数据拉取。他们在 Sales Nav 或 ZoomInfo 中设置一些职位和资历筛选条件,导出名单,再推给销售代表。之后,销售代表要花上数小时逐个点击个人资料,试图弄清楚到底谁真正值得联系。这里没有文档化的逻辑,团队内部也没有一致性,而这些标准都只存在于某位资深成员的脑子里。一旦这个人离职,或业务扩展到他自己无法继续亲自处理的程度,这种判断力也会随之流失。
AI 带来的可能性
你可以提取这种判断力,将其文档化,并以程序化方式运行——这样每个账户中的每个联系方式都能按照相同标准进行评估,并且可以大规模执行,同时不会消耗销售代表的时间。
具体做法如下。
第 1 步:根据现实验证你的联系人理论
在评估个体之前,先严格检验一下你对实际销售对象的假设。
大多数团队对于哪些人物画像重要都有一套基本判断——职能、资历级别、角色类型。把这些写下来。然后从你的 CRM 中导出两类数据:过去 6–12 个月内主动咨询的联系方式,以及与已成交交易相关联的联系方式。将两者都上传到 Claude 或 ChatGPT,并让它总结其中的模式。
提示词示例:
“这里有两个 CSV 导出文件:近期入站联系方式,以及与已成交优惠关联的联系方式。识别哪些职能、职位头衔和资历级别出现得最频繁。标记任何在已成交优惠中经常出现、但不在我们当前 persona 列表中的头衔或职能。”
你要找的是意外发现。那些你没预料到的角色。那些在你的优惠中反复出现、却不在你的目标列表中的职能。这会给你一套经过验证的筛选条件——基于实际奏效的内容,而不只是听起来正确的东西。
第 2 步:在开启语音听写的情况下进行人工审核
从少数几个账户中提取联系人列表——如果有的话,混合不同细分市场和垂直行业——然后让你们经验最丰富的人在 LinkedIn 上逐个查看每个个人资料,并大声说出来。
关键是在实时捕捉其中的为什么 。使用听写工具(Wispr Flow 和 Monologue 都很好用),让他们边点击边口述:是什么吸引了他们的注意、是什么让他们犹豫、他们会先联系谁以及原因是什么。不要对其进行筛选——你需要的是原始推理过程,而不是经过润色的总结。
要获取联系人:使用第 1 步中的筛选条件在 Sales Navigator 中构建搜索,然后使用浏览器自动化或导出工具导出潜在客户——PhantomBuster、Evaboot 和 Captain Data 都能很好地完成这项工作。
你需要留意的是:
-
个人资料中的措辞是否体现出前瞻性还是固化思维——他们描述的是成果还是任务?
-
资历和成长轨迹——他们是否随着时间推移在公司内部获得了晋升?
-
该职位头衔是否反映出真正的负责范围,还是一个职责有限的个人贡献者角色
-
公司规模如何改变职位头衔的实际含义
最后这一点的重要性,往往超过大多数团队的预期。一位来自 50 人规模公司的 “Director of Sales” 很可能负责整个职能。拥有相同头衔的人在 2,000 人规模的公司里,可能只管理一个区域。最终,你可能需要按细分市场制定独立的标准。
第 3 步:用 AI 综合模式
评审完成后,将你的笔记(或口述转录文本)上传到 Claude,并要求它综合总结你的发现。
示例提示词:
“以下是我在审查 [X] 个联系人个人资料时做的笔记。找出那些让某人成为‘是’与‘否’的稳定信号。按主题进行分组——资历信号、语言模式、角色职责等。然后标记出任何特定于公司规模或细分领域的模式。”
你并不是在让 AI 凭空发明你的标准。你是在让它找出某种你已经知道之事的轮廓。输出结果应当读起来像是你最优秀的审查者一直在脑海中进行判断的文档化版本。
仔细审阅这份综合结果。在它过度简化的地方提出质疑。在它遗漏细微差别的地方补充细节。你最终得到的将是一个资格判定框架——你真实的标准,被写了下来,并已准备好转化为一个 prompt。
第 4 步:分别构建你的分类与资格评估 Agents
这是在 MedScout 通过惨痛教训学到的一点:不要试图一步同时做分类和资格判断。把它们合在一起时,评估就会变得模糊——你最终会同时试图弄清楚某人是做什么的以及他们是否相关,而这两个问题的答案都会受到影响。
拆开来做:
先分类
构建一个 prompt,根据每个 contact 的 LinkedIn profile 将其映射到某个职能类别。他们实际属于哪个桶——销售、运营、市场、财务等?同样的职位名称在不同公司可能意味着不同的事情。先把职能判断准确,后续的匹配判断就会更清晰。
示例提示:
“根据这个 LinkedIn 个人资料,将此人的主要职能归类到以下类别之一:[your function list]。使用他们的职位、当前职责描述和职业经历。如果存在歧义,默认归入其近期职位中占比最高的职能。”
第二步:资格判断
现在你已经知道他们是做什么的,接下来评估是否匹配。他们是否属于那种会推动或影响像你们这样的工具评估的人?答案是一种整体判断——资历、职责范围、职能所有权,以及他们如何描述自己的工作。
按层级构建输出,使其映射到行动,而不仅仅是质量:
-
最佳匹配: 值得在触达中优先考虑——他们会主导或强烈影响评估过程
-
适配度高: 值得纳入 CRM 并进行触达,但不是你优先接触的人
-
不匹配: 不值得进行外联
如果你的细分市场存在显著差异(例如 SMB 与 enterprise),请为每个细分分别构建独立的资格判断提示词。两者的采购动态差异足够大,一套标准无法同时清晰覆盖这两种情况。
第 5 步:将工作流程投入运行
一旦你的提示词经过测试并值得信任,就将它们加载到工作流自动化平台中。Clay、Apollo 和 Cargo 都是为这种多步骤的丰富与资格判定流程而构建的。
工作流:在你的联系人数据库中构建联系人列表 → 导出线索 → 用 LinkedIn 个人资料数据进行丰富 → 运行你的分类提示词 → 运行你的资格判定提示词 → 将合格联系人连同已标记的来源和日期推送到你的 CRM 中。
后端有几件事需要做好:
-
在推送新联系人之前,先与现有 CRM 记录进行去重
-
为每条记录标记补充信息来源和日期——当你之后需要审计数据质量时,你会感谢现在的自己
-
不要为每个账户中的每个联系人都做补全。应为那些已经完成资格认定的账户中真正重要的联系人做补全。顺序很重要:先进行账户资格认定,再进行联系人资格认定,最后再做补全。
目标是把工作方式颠倒过来。不再让每位销售代表都花上数小时在 Sales Nav 里试图弄清楚该联系谁,而是由系统筛选出合适的人选,并提供足够的背景信息,让销售代表能够快速响应并做出最终判断。这样节省下来的时间会迅速产生复利效应。
什么才算好
一个构建良好的联系人资格判定代理会为每位联系人返回类似这样的结果:
职能分类: RevOps / 销售运营
匹配层级: 最佳匹配
理由: 总监级别,且使用了明确的负责表述——描述了“从零开始搭建预测流程”和“负责 tech stack”。公司规模为 300 人,因此这个头衔反映了实际职责范围。职业经历显示其在该职能内持续成长。
建议操作: 在触达中优先处理。很可能是经济或技术评估者。
这类输出才是你希望销售代表据以做出反应的——而不是原始的 Sales Nav 个人资料。
注意事项
不要跳过人工审核阶段。 直接开始构建 prompts 很有诱惑力。但你的 AI agent 的效果只取决于你提供给它的标准——而这些标准必须来自对真实 profiles 施加的真实判断。人工这一步并不低效。它就是输入。
比你认为需要的时候更早进行细分。 如果你的 ICP 同时覆盖 SMB 和 enterprise,不要试图用一个 prompt 同时处理两者。在一家 50 人公司的 “Best Fit” 信号,与一家 5,000 人公司的会有所不同。尽早据此构建,否则你之后还得重建。
本指南中提到的工具
本指南聚焦于方法论——如何提取、记录并将你团队对联系人的资格判断操作化。具体使用哪些工具可以互相替换。以下是文中提到的类别和选项:
– 联系人数据库 (按职位、职能、资历、公司搜索和筛选潜在联系人):LinkedIn Sales Navigator、ZoomInfo、Apollo
– 联系人导出 (将联系人列表从你的数据库拉取到可操作的格式中):PhantomBuster、Evaboot、Captain Data
– 数据补全与工作流 (用附加数据补全个人资料,批量运行 AI 提示词,管理 pipeline):Clay、Apollo、Cargo
– 听写 (在人工审核过程中捕捉口头推理):Wispr Flow、Monologue
– AI 助手 (整合模式,构建分类和资格判断提示词):Claude、ChatGPT
选择适合你技术栈的工具。本指南中的框架适用于所有这些工具。