AI 的火箭燃料
作者:Astasia Myers GP @ Felicis | 来源:SandHill.io
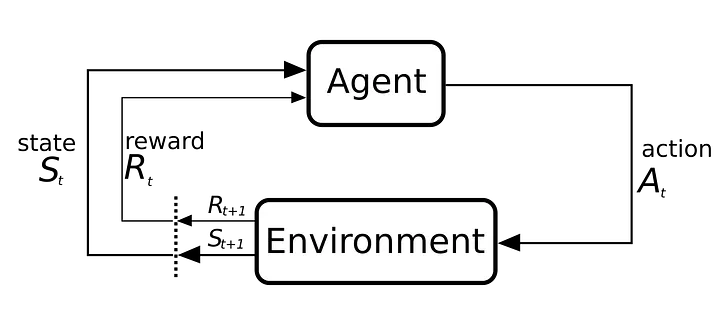
对于 AI 平台的转型而言,强化学习就是火箭燃料。
在过去的六个月里,新一波强化学习(RL)技术一直在积聚势头。两个独特但互补的趋势脱颖而出:大规模可扩展的 RL 环境和“强化学习即服务”(RLaaS)云平台。这些创新有望改变 AI 系统的学习和适应方式,从静态训练转向动态的、持续的改进。
在 Mercor 等公司不断推动 RL 促进 AI 发展的边界的同时,像 Kaizen、Mechanize 等平台正试图让使用 RL 变得像启动虚拟服务器一样简单。
鉴于 RL 的巨大重要性,理解这些技术各自包含什么、它们为何在增长,以及它们为 AI 的未来提供了怎样的机遇,都至关重要。
RL 的时刻:从静态模型到动态学习者
今天大多数的 AI 模型都是在巨大的数据集上训练一次,然后就固定不变。它们能力非凡,但也是静态的。一旦训练完成,它们不会轻易地自行改进或适应新任务。RL 为超越这一局限性提供了一条路径。在 RL 中,一个 AI 智能体通过与环境互动来学习,尝试不同的行动,并接收反馈(奖励或惩罚)来完善其行为。
这种试错循环可以产生动态的、自适应的智能体,它们能从经验中持续学习。其前景是,AI 不再仅仅是复述训练数据,而是能通过实验真正弄清楚如何完成目标,无论是控制机器人、优化业务流程,还是编写软件功能。
当奖励是可验证的(正确或不正确)时,RL 最为成功,例如在软件开发和数学领域。对于更复杂的场景,其中正确性可能更具主观性,像 OpenAI GPT-5 这样的团队使用一个通用验证器,该验证器通过使用各种来源进行研究,逐步验证正确性,从而自动检查和评分另一个模型的输出。通用验证器对于将 RL 扩展到正确性更模糊的新用例至关重要。
然而,大规模利用 RL 需要两个直到最近还很稀缺的东西:(1)丰富、现实的环境,智能体可以在其中安全地练习复杂任务,以及(2)可访问的基础设施,用于运行大规模的 RL 训练,而无需每家公司都拥有昂贵的研究实验室。这就是两种新兴技术的用武之地。让我们深入探讨每一种。
强化学习环境:AI 的虚拟工作与游乐场
RL 环境是一个模拟世界或场景,AI 智能体可以在其中行动和学习。经典的例子包括视频游戏或机器人模拟器,但最新的趋势是构建模拟现实世界工作任务的环境。这些环境可能模拟使用计算机、编写代码、填写表单、回复电子邮件,或人类在知识工作中执行的任何长周期任务。通过在这种现实的模拟中训练,RL 智能体可以获得对自动化实际工作有用的技能。
这是一个类似于 GPT-3 为自然语言处理(NLP)所做的范式转变:大规模扩展训练数据和环境,以便最终的智能体能够泛化到广泛的挑战中。
我们遇到过一些初创公司,它们正在汇集大量真实的软件界面(如 Salesforce 或 Excel)集合,并捕获完整的交互数据,以便智能体可以在真实的企业环境中学习。这个 RL 环境构建者的生态系统正在迅速发展,其驱动力在于一个洞见:更智能的智能体需要更丰富的游乐场。
另外,Mechanize 引入了一个他们称之为“复制训练”的概念。在这些场景中,AI 智能体被给予一个软件或工作流的现有实现,并被要求根据其规范重新创建它。这允许根据参考实现自动评估智能体的输出,为学习提供了强烈的信号。随着时间的推移,通过数千次此类复制的训练,模型可以掌握现实世界的技能,如注重细节、任务分解和错误恢复——这些是自动化有意义工作所必需的能力。
RL 环境平台正在成为任何希望训练通用型 AI 工作者的基础性设施。
强化学习即服务:为每个人提供按需的 RL
如果说 RL 环境是“训练场”,那么强化学习即服务(RLaaS)则使学习过程可扩展并为他人所用。像 Applied Compute、Veris 和 Osmosis 这样的 RLaaS 提供商提供托管平台,公司可以在这些平台上根据自己的目标训练 RL 智能体,而无需内部的 RL 专业知识。通过利用专有数据,企业可以创建针对特定应用进行优化的定制模型。一个流行的用例是金融服务的后台自动化。RLaaS 平台支持持续改进,其反馈循环会随着时间的推移而增强,使智能体能力越来越强,越来越难以被取代。随着业务需求的发展,RLaaS 确保 AI 系统也随之发展。
宏观趋势与展望
纵观环境和服务两个方面,有几个主要力量脱颖而出:
通过规模实现泛化:与 GPT-3 和其他基础模型一样,人们相信足够多样化的训练(在这种情况下,通过环境)会导致涌现出通用的能力。期望在数千个不同任务中实践的 RL 智能体能发展出更强、可迁移的技能。我们相信 RL 将成为构建最强大智能体的关键部分。正如康奈尔大学博士 Jack Morris 所说,RL 正日益成为扩展的新轴心。
持续学习:RL 使模型能够随时间适应,而不是在训练后保持冻结状态。这种动态能力对于边缘案例、用户偏好或环境频繁变化的应用尤为重要。Osmosis 专注于实时 RL,因此 AI 智能体可以持续改进,无需人工干预。
RL 的企业应用:过去属于研究实验室的领域现在正走向企业 AI。RLaaS 使得使用持续的反馈循环来优化特定业务指标(如转化率或满意度分数)成为可能。
基础设施机遇:RL 的兴起引发了解决核心工具问题的初创公司激增,从模拟环境到训练编排再到奖励工程。就像云计算的早期一样,对可扩展、安全和可组合的 RL 基础设施的需求日益增长。
AI 智能体评估和可观察性仍然重要:AI 智能体轨迹的详细追踪与评估指标相结合,有助于为智能体优化形成有价值的奖励信号。像 Judgment Labs 这样的产品为这一过程提供了便利。
RL 正在从一种小众技术演变为构建自适应、自主 AI 系统的强大能力。无论是通过像 Kaizen 这样模拟真实工作的平台,还是像 Applied Compute 这样简化 RL 的服务,它都变得越来越可用和有影响力。
最激动人心的前沿可能在于这些技术之间的协同作用:高度能力的训练环境为云原生 RL 管道提供养料。它们共同承诺了一个世界,在这个世界里,AI 智能体不仅能理解,还能行动、适应并持续改进。最激动人心的前沿可能在于这些技术之间的协同作用:高度能力的训练环境为云原生 RL 管道提供养料。它们共同承诺了一个世界,在这个世界里,AI 智能体不仅能理解,还能行动、适应并持续改进。
对于技术创始人来说,这是一个构建工具、平台和产品的机遇时刻,将这些能力带给数百万人。
在未来几年,预计 RL 将从研究实验室走向主流应用。今天构建环境和服务的公司将塑造机器未来学习的方式。





