工作的暗物质
作者:Evan O’Donnell | 来源:SandHill.io
工作的暗物质
本文描绘了一类新型 AI 产品,它们观察人类与智能体的工作方式,然后将所学编码成一个新的数据层。这些产品被构建为随着模型的改进而变得更强大、更具防御性。
01 | 工作的暗物质
当前是构建和投资新技术的困难时期。模型能力提升如此之快,以至于许多 AI 原生产品,即使是那些具有实际效用和吸引力的产品,也正在迅速变得过时。
在我自己的尽职调查中,我不得不非常、非常努力地思考这个问题……
如果模型性能提升 50 倍,为什么这款产品仍然有存在的权利?
为了理清思路,我从模型的根本优势入手。
当今的模型将非结构化输入转换为输出。它们在三件事上表现得异常出色:(i) 理解和生成语言、代码和图像;(ii) 对多步骤问题进行推理;以及 (iii) 在软件系统中执行命令。它们每天都在这些任务上做得更好。
如果你的产品的价值主张完全依赖于在这些维度上增强 AI——更智能的推理、更好的检索和上下文管理、更深的领域专业知识——那么你距离被淘汰只有一个模型版本的距离。
持久的产品价值必须来自其他地方。不是通过弥补智能能力的短期差距,而是通过为 AI 创造全新的输入来发挥作用。
换句话说,最好的产品策略不是让 AI 更智能——而是扩展 AI 的视野。毕竟,任何模型,无论多么强大,都只能基于它所观察到的内容进行推理。
这原来是一个旧概念。
1991年,Ikujiro Nonaka 发表了历史上被引用次数最多的管理学论文之一——《创造知识的公司》。他的论点是,组织依赖两种知识运行。
显性知识很容易被编码——一个流程、一份政策文件、一个决策树。隐性知识则是技艺。它存在于人类的直觉、实践和判断中。它是那位知道哪些客户需要预先致电的客户成功经理。或者是那位在日志于生产环境中发现问题之前,就能感觉到代码库哪些部分很脆弱的工程师。
隐性知识是工作的“暗物质”——连接原始信息与行动的无形推理、意图和机构记忆。它不存在于任何记录系统中。它在日常工作过程中,通过人类行为短暂地表达出来。
直到现在。
一类新的 AI 产品正开始捕捉这个无形层面——不是通过要求人们记录他们所知,而是通过直接观察他们的工作方式……
……视觉模型在数千个日常会话中感知应用程序内的用户活动……
……语言模型从分散在 Slack 和电子邮件中的员工对话中提取推理……
……代码溯源工具将每个 AI 生成的函数追溯到提示、智能体的思维链和开发人员的修正。
这些产品不是在预先存在的数据库之上嫁接 AI。它们正在产生一种根本上新型的数据资产——一个前所未有的、动态的、情境化的层面。
02 | 让无形变得有形
这在实践中是什么样子的?这个类别中最强大的产品共有四个特性。
1/ 它们生成一种根本上新型的数据资产。一种从未出现在任何记录系统中的资产。
2/ 它们不仅捕捉发生了什么——它们还编码了为什么。原始行为数据被翻译成一种意义的表示,一种机器可以读取和行动的表示。
3/ 它们的观察是持续且自我强化的。系统静静地观察人们如何工作,提炼模式,并将其反馈到产品中以提高准确性和自动化水平。这反过来又推动了更多的使用,从而产生更多的数据用于学习。
4/ 它们创造了一个其他人可以构建于其上的数据原语。第三方智能体和产品有动机去集成和消费的结构化上下文。
一些早期产品已经在朝这个方向发展:
示例 #1:开发者工具 // ENTIRE.IO
Entire 正在为代码构建一个新的存储和溯源层。
创始团队来自 GitHub,亲眼目睹了 git1 在 AI 时代的局限性。具体来说,git 将代码存储为文本文件并跟踪版本历史,但没有机制来捕捉代码的含义或编写原因。
当人类编写每一行代码并将设计记在脑中时,这没有问题。但当代码生产外包给 AI 智能体时,这就行不通了。
Entire 通过将这个无形层面——代码的历史和意义——显性化来解决这个问题。
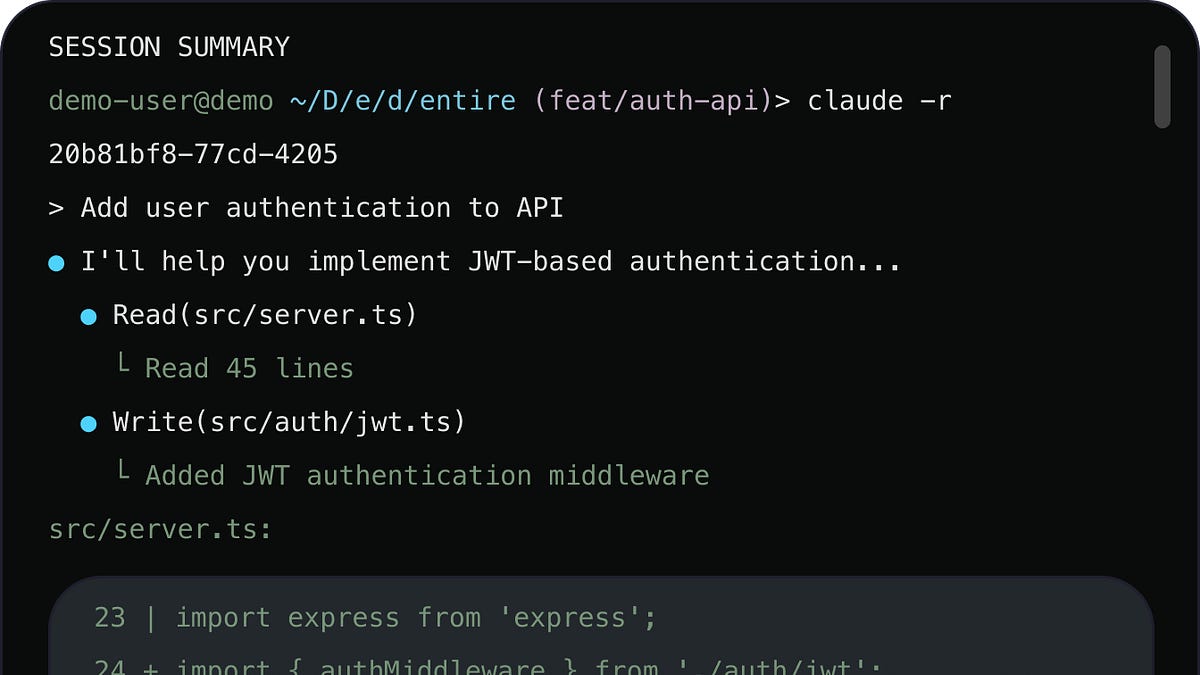
他们的第一个产品 Checkpoints,会自动从 IDE2 中捕捉完整的智能体编码会话——所有提示、智能体输出和推理,以及开发人员的修正。当开发人员提交3到存储库时,该上下文会作为结构化的、可查询的资产永久链接到代码,可供未来参与该项目的每个智能体和工程师使用。
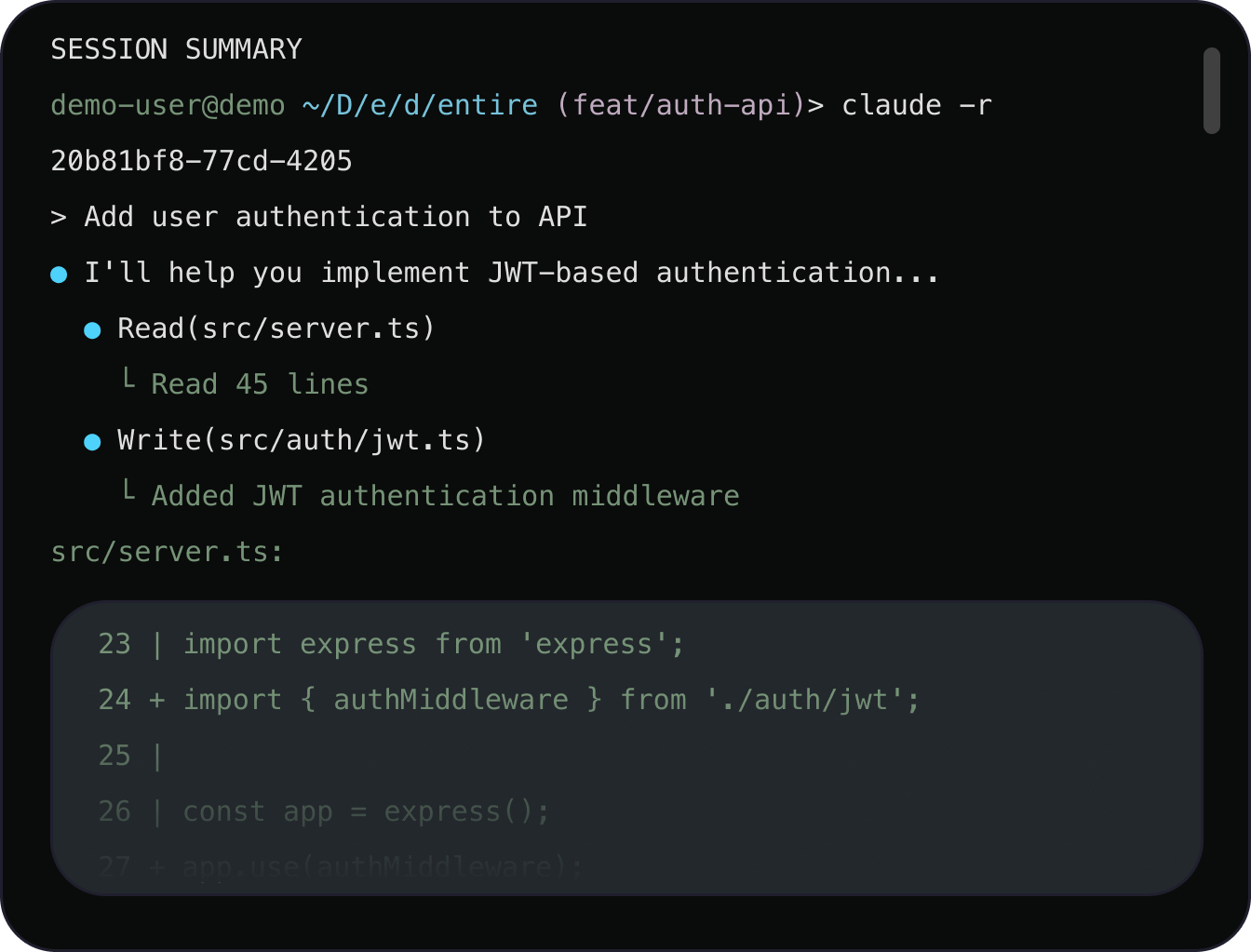
在这里,每个编码会话都有助于系统对代码、其相互依赖关系以及其形成过程的理解。随着时间的推移,这将代码仓库从一个静态存储档案转变为一个活生生的记录,每一次提交都使其更加健壮。
而更好的模型只会放大这一优势,因为随着更智能的智能体进入市场,它们可以从完整的上下文和历史中提取更多、更新类型的价值。
示例 #2:水平软件 // WORKTRACE.AI
Worktrace 正在构建下一代 RPA4 产品。创始人来自 OpenAI,他看到企业采用 AI 的最大瓶颈不是技术——而是知道要自动化哪些工作流,以及如何实现。
如今,确定要自动化的内容是手动且缓慢的——团队要么手动绘制流程图,要么依赖 UiPath 或 Zapier 中的软件工具,这些工具捕捉点击和数据流等表面行为。
Worktrace 取代了这一切。
该产品与 Slack 和 Linear 等现有工具集成,静静地观察员工如何工作。但它超越了表面层次的流程映射——它解析意图,捕捉员工为何采取某些行动,以及他们如何以不同方式完成相同任务。为什么协调员在时间压力下会跳过某些步骤?为什么两个人遵循不同的路径达到相同的结果?
输出是一张按潜在影响排序的自动化机会优先图,并附有概述了每项任务的正确 AI 模型和智能体设计的规范。
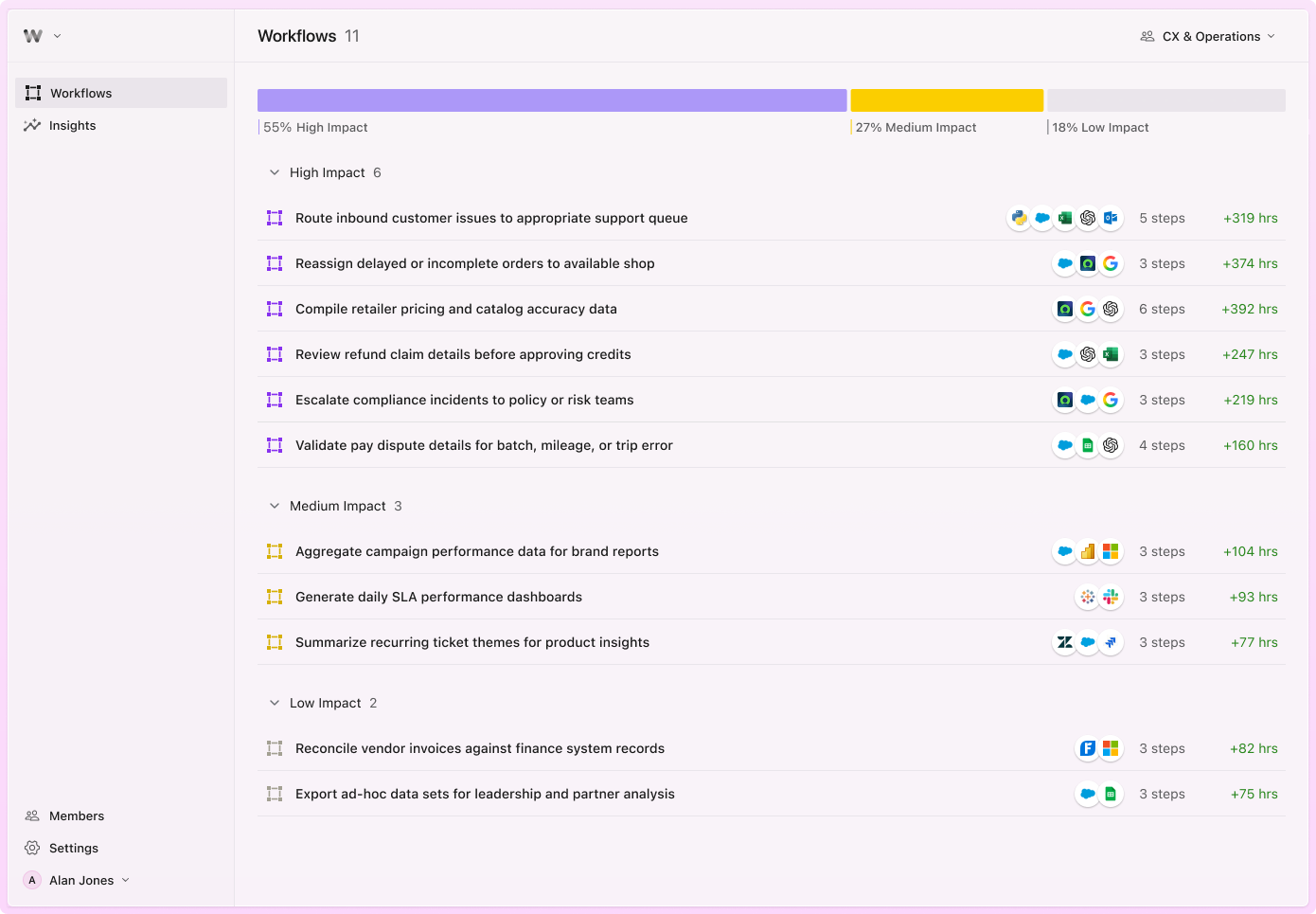
Worktrace 并非在“更好的自动化”上竞争,而是拥有一些更难复制的东西——对员工实际工作方式以及 AI 在何处能产生最大影响的细致入微且动态的理解。
随着模型的改进,会发生两件事:(1) 实时观察能捕捉到更丰富、更复杂的工作流模式,以及 (2) Worktrace 可以重新审视其积累的历史,以发现早期模型无法检测到的自动化机会。
换句话说,随着 AI 的加速发展,该产品只会变得更有价值。
03 | 持久产品的剖析
还有许多其他产品——遍及生产力、垂直 SaaS 和开发者工具——正在开发类似的架构。每个产品表面上看起来都不同。但在底层,它们共享相同的产品模板。
步骤 1:感知机制
这些产品需要一种方法来观察先前对软件不可见活动和行为,通过观察应用程序内部和跨应用程序的活动来实现。
这种能力不同于知识图谱或上下文图谱,后者组织的是现有系统已产生的数据工件之间的关系。例如,知识图谱可能会映射支持工单、客户账户历史和升级该工单的客服之间的关系。但所有这些数据已经存在于某个数据库中。而观察模型则捕捉那些不存在的数据——比如解释工单最初为何被升级的 Slack 私下沟通。
一些顺风因素正在使这种观察能力变得可行且更高效。
像蒸馏5和量化6这样的技术现在允许小型的、专用模型在手机和笔记本电脑上本地运行,使得观察流程中的简单任务(如数据捕获和实体提取)可以在边缘设备上进行。这可以提供一个更便宜、更安全的架构,因为原始数据不需要离开设备。
此外,多模态模型现在可以同时处理视觉、音频和文本,而不需要为每种模态使用单独的模型。随着多模态能力的提高,这极大地扩展了软件可以感知和分析的行为范围。
步骤 2:将原始输入转化为意义
大部分产品价值——即“秘方”——在于这些系统如何将感知(来自步骤1)转化为结构化的、语义化的数据。
具体的策略和实现方式各不相同,取决于产品和类别。但在评估一个产品是否做得好时,有几点可以参考:
输出是否被模式化为已定义的实体、字段和关系?它是否是机器可读的?
输出是否可转移?它能否以最小的转换直接插入第三方智能体构建器、API 或自动化管道?
输出是否编码了意图和决策逻辑(“为什么”发生某事),而不仅仅是行为遥测(“什么”发生了)?
系统能否成功处理边缘案例和可变性,识别出不同行为何时针对相同的最终目标?
步骤 3:建立反馈循环
来自步骤 2 的输出会流回产品中。这通常通过以下两种方式实现:(i) 上下文丰富(先前的数据和观察结果被存储和组织起来,以帮助智能体在未来的会话中轻松查找和访问),或 (ii) 模型调整和微调(交互数据和输出被用来重新训练在步骤 1 中进行观察和在步骤 2 中进行转换的模型)。
04 | 外部化,工业化
Nonaka 明白,公司真正的竞争优势来自于外部化——将人类直觉和技艺转化为他人可以使用的东西的能力。在 1991 年,这是通过语言和人类对话完成的。
“这三个术语捕捉了组织将隐性知识转化为显性知识的过程:首先,通过隐喻连接矛盾的事物和思想;然后,通过类比解决这些矛盾;最后,通过将创造的概念结晶并体现在模型中,使知识可供公司其他人使用。”
- Ikujiro Nonaka, 《创造知识的公司》 (1991)
对 Nonaka 来说,外部化总是受限于人类的带宽——对话、管理和指导的缓慢工作。
但 AI 消除了这一限制。本文中讨论的产品将人们工作的原始、非结构化的混乱状态转化为语义意义。
这是工业化的外部化。
今天能胜出的产品不会凭借“更好的 AI”或“更好的智能体”成功。它们将为工作开发一个新的感官层——一个能观察到任何系统都未曾记录过的内容,将其翻译成机器可读的意义,并允许该知识语料库随着时间的推移有机地建立起来。
能够正确构建这种架构的公司不仅能在下一次模型发布中幸存下来。它们会因此变得更强大。
它们将把工作的暗物质带入光明。





