内存三巨头 | Wing Venture Capital

SK海力士、三星和美光如何成为AI领域最集中的控制节点——以及为何HBM占每块英伟达GPU销售成本的50%以上。
来源: https://www.wing.vc/content/the-memory-triopoly
观点
我们最近一直在谈论内存——从跨Prefill和Decode阶段的KV Cache动态,到内存本身作为AI计算的结构性瓶颈。约束条件不再是原始FLOPS。而是能否足够快地将字节移入和移出这些FLOPS,以保持日益庞大的模型得到持续供给。
三家公司——SK海力士、三星和美光——掌控着这个瓶颈。它们控制着约96%的DRAM市场,以及实际上100%的高带宽内存(HBM)。HBM现在是英伟达加速器内部最具经济关键性的单一组件,占Blackwell Ultra(B300)物料清单的50%以上,并且在Rubin平台上占比更高。
在HBM经济周期的顶峰,SK海力士的盈利能力开始超过像Meta这样购买其产品的超大规模企业。综合来看,内存三巨头在2026年的预计净利润将是Meta的2-3倍。
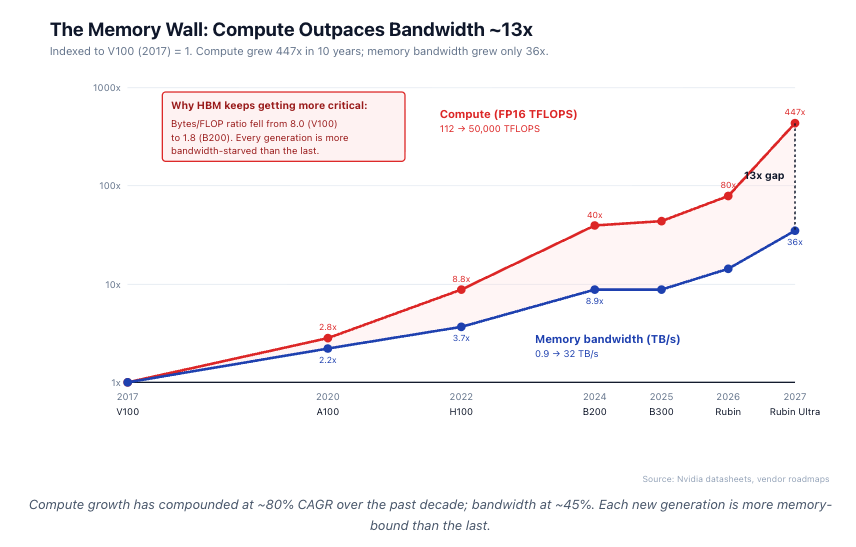
计算能力增长快于内存
每一代英伟达产品都遇到了同样的障碍:内存。在11年间,每块GPU的内存容量从P100到Rubin Ultra增长了约18倍。同期,FP计算能力增长了约500倍。
其结构性含义是:每一代AI产品都变得更加受带宽限制。内存已从GPU BOM(A100)的约20%上升到约55%(B200)。对于Rubin,HBM的成本可能超过逻辑芯片本身。我们正开始接近在处理器上放置HBM的物理极限。GPU的 shoreline 由芯片周长决定,而HBM堆叠只能沿着四个边缘中的两个放置——这就是为什么Rubin Ultra通过增加高度而非宽度来扩展到16个堆叠。
HBM物料清单与利润捕获
一块B200有8个HBM3E堆叠,每个24 GB(总共192 GB)。HBM在B200 GPU BOM中的占比约为52%,在B300(Blackwell Ultra,288 GB HBM3E 12-Hi)中约为58%,根据早期ASP指引,在Rubin(HBM4)中预计约为62%。
英伟达B200的标价在30,000至40,000美元之间。每增加一美元B200收入,大约有0.10至0.15美元作为毛利润贡献流向HBM供应商。SK海力士捕获其中的约45-50%。三星约30%。美光约22%。
内存供应商现在与英伟达的收入轨迹紧密相连,其紧密程度可能超过了现代半导体历史上任何供应商-客户关系。
每GB成本:残酷的层级结构
内存不是一个单一市场。它是一个分层的堆叠,成本差异高达六个数量级。
HBM3E每GB成本约为DDR5的6倍,但每个堆叠的带宽是其25倍。在每(GB·带宽)成本的基础上,对于超过一定计算密度的AI工作负载,HBM是唯一经济合理的选择。
SRAM每GB的成本比HBM高出两到三个数量级。而且SRAM的扩展已经停滞。从台积电N7到N5,SRAM密度仅提升了5%。从N5到N3,提升再次不到5%。历史上关于片上缓存能与逻辑性能同步提升的假设已经失败。
这就是SRAM扩展的悬崖。任何依赖大型片上缓存的AI架构(如Cerebras、Groq风格的方法)都面临着日益严峻的成本曲线。HBM仍然是唯一结合了大容量、高带宽和可接受成本的内存技术。
内存墙,量化分析
AI的核心架构问题不再是计算稀缺。而是内存饥渴。
AI工作负载受三个物理约束限制,而非FLOPS:
- 现代GPU每字节所需的计算量远高于Transformer工作负载自然产生的计算量。每个GPU都有一个平衡点——即每获取一字节内存可以执行多少次数学运算。对于V100(2017年),平衡点约为每字节125 FLOPS。对于今天的B200,约为每字节560 FLOPS。要让GPU满负荷运行,软件需要对其接触的每个字节执行那么多次运算。Transformer解码工作负载远低于这个阈值。典型的解码工作负载每获取一字节仅执行1-10次运算——它们大部分时间都在等待内存。结果是:AI芯片在推理过程中通常只能达到峰值FLOPS的15-35%。每增加1 TB/s的HBM带宽,都会直接转化为利用率恢复和更低的每Token成本。
- KV缓存现在主导着推理内存。在推理过程中,每个先前Token的“键”和“值”表示必须保留在内存中,以便下一个Token可以关注它们。这就是KV缓存,它随着上下文长度×批次大小而增长。在128K上下文、批次大小为32的情况下,Llama 3 70B仅KV缓存就需要约80 GB——比模型权重本身还多。在1M上下文时,每个请求的KV缓存超过600 GB。这就是为什么H200的141 GB和B200的192 GB相对于H100的80 GB是一个阶跃变化:不是因为权重变大了,而是因为缓存变大了。
- 移动数据比计算数据消耗更多能量。通过HBM移动一个比特大约需要7皮焦耳。通过封装外的DDR5:80皮焦耳。来自片上SRAM:0.1皮焦耳。在4纳米节点上执行一次8位乘法:0.05皮焦耳。在万亿次运算规模的推理中,数据移动的能量消耗超过计算能量的3-10倍。这就是为什么每一种架构响应——带有逻辑基础芯片的HBM4、堆叠SRAM、存内处理——从根本上都是为了减少每移动一字节所消耗的焦耳数。
经济层面的转化:HBM带宽是AI基础设施中杠杆率最高的资本支出决策。对于现代Transformer工作负载,额外HBM带宽的边际价值通常超过其边际成本。
HBM堆叠究竟是什么
来源:高带宽内存,Semi Engineering

高带宽内存,Semi Engineering
在讨论供应商差异之前,先快速了解一下工程图景。HBM不是一个芯片——它是一座由芯片组成的小型摩天大楼。
一个HBM3E 12-Hi堆叠是十二个DRAM芯片堆叠在一个逻辑基础芯片之上。每个DRAM芯片被研磨至约30微米厚——大约是人类头发丝的三分之一——因此整个塔可以封装在内部。这些芯片通过硅通孔(TSV)垂直连接:在每个芯片上钻出填充铜的孔,直径5-10微米,间距约50微米。一个12-Hi堆叠每层有1,200-1,800个用于数据和电源的TSV,外加数千个用于信号完整性。
该堆叠位于GPU计算芯片旁边的硅中介层上。中介层是布线层,承载着内存与计算之间1,024位(HBM3)或2,048位(HBM4)的总线,其走线密度和阻抗是有机基板无法比拟的。对于英伟达加速器,相关的实现是台积电的CoWoS-L。
三件事使得HBM难以制造:
- 热量。每个堆叠耗散4-8瓦特。这些热量必须向上穿过十二层薄硅片及其间的粘合剂。热极限是为什么H100在2022年推出时只有六个可能的HBM3堆叠中的五个处于活动状态——第六个插槽被保留作为热容限和良率裕量。
- 良率叠加。一个坏的TSV就会毁掉整个堆叠。在每芯片99%的良率下,一个12-Hi堆叠的良率为88.6%。在每芯片95%的良率下,仅为54%。这就是为什么在HBM规模下,每芯片良率比标称密度更重要——也是为什么SK海力士75-80%的1bnm良率是一个比数字本身所暗示的更宽的竞争护城河。
- 更宽的IO优于更快的IO。HBM4将接口从1,024位翻倍到2,048位,但保持每引脚速度与HBM3大致相同(约6.4 Gbps)。更宽且更慢的方式每比特功耗更低,并且在现代中介层密度下比更窄且更快的方式良率更好。这一选择迫使基础芯片转向逻辑代工厂节点(台积电N5/N3)而非DRAM生产线,并决定了哪些供应商能够制造它。
有两种物理堆叠芯片的方法:
- MR-MUF(批量回流焊与模塑底部填充)——SK海力士的专有方法。在单个热循环中键合并填充芯片之间的间隙。更好的导热性,层间空隙更少。
- NCF(非导电薄膜)——三星的方法。预涂薄膜逐层键合。设备成本更低,每个堆叠速度更慢,历史上良率更低。三星修订后的“Advanced TC-NCF”缩小了差距,但并未消除与HBM4的差距。
层数持续攀升。HBM4支持16-Hi配置——是HBM3推出时的两倍。早期的720微米封装上限无法容纳16-Hi堆叠,迫使标准在2024年底扩展到775微米。更高的封装意味着微凸块在HBM4中仍然可行,而期待已久的直接铜对铜键合已推迟到HBM4E或更晚。
一旦铜对铜键合到来,互连间距将急剧缩小,同时完全消除芯片之间的凸块间隙——从而实现更高的堆叠密度和更低的每比特功耗。代价是出现一个新的瓶颈:混合键合工具产能。
HBM市场份额,2024-2026年预估。SK海力士的垄断时代已经结束;三星的HBM3E 12-Hi认证和美光的产能爬坡已将领先者的份额压缩了7个百分点。2025年HBM总收入仍以超过100%的速度复合增长。
三巨头的数字
DRAM是一个三头垄断市场。HBM不再是SK海力士的垄断——三星的HBM3E 12-Hi在2025年第四季度通过英伟达认证以及美光的产能爬坡,已在18个月内将领先者的份额压缩了约7个百分点。但HBM总收入继续以超过70%的同比速度复合增长,因此三家公司的绝对收入都在增长。
自2010年以来,经历了五个DRAM周期,该行业从10多家供应商整合到三家。每一次低迷都淘汰了边际产能。结果是内存历史上最高的持续定价能力:HBM3E每GB ASP是传统DDR5的6-8倍,HBM4 ASP约为10倍,并且产能到2027年已完全售罄。
SK海力士——HBM领导者
第一大HBM供应商,市场份额约45%,是英伟达H100的HBM3独家供应商,现在也是Rubin的HBM4主要供应商。
技术护城河是双重的。SK海力士的1bnm DRAM良率在75-80%之间,而三星的1cnm良率在60-65%之间——这个差距在12层堆叠芯片中会叠加放大。其专有的MR-MUF堆叠工艺使其在HBM3E 12-Hi上保持超过80%的良率,独树一帜。
展望未来:SK海力士于2026年3月向英伟达交付了首批HBM4 12-Hi样品——在Rubin插槽竞争中领先竞争对手6-9个月。HBM4基础芯片在台积电N5节点制造,在最先进的节点上耦合了内存和逻辑护城河。
主要风险:英伟达约占其总收入的42%,是现代半导体行业中最紧密的单客户关系。
三星——垂直整合的回归
按资本支出计算最大的内存公司,但在HBM3周期中失利。2023年在英伟达出现热故障,1anm节点良率不达标,以及较慢的TC-NCF堆叠,使三星远远落后。
故事在2026年发生了转变。1cnm DRAM良率在2026年第一季度收敛至约65%。HBM3E 12-Hi于2025年11月通过英伟达认证。“Advanced TC-NCF”缩小了堆叠差距。而AMD的MI400现在主要承诺使用三星的HBM4——这是三星在本周期内首次完全赢得的主要AI插槽。
其他公司没有的结构性优势:三星是唯一一家同时拥有自己逻辑代工厂的内存公司。随着HBM4E在2027年转向客户特定的逻辑基础芯片,三星可以共同设计内存和基础芯片,而无需跨越公司边界。
主要风险:在HBM4上仍落后SK海力士6个多月。2027年的HBM4E代际是三星的集成理论必须实际证明自己的时候。
美光——美国对冲
三者中最小,但有两个独特的优势。
不同的DRAM单元架构。美光使用“开放式位线”拓扑结构,带有垂直电容器,而SK海力士和三星使用平面设计。美光声称在相同带宽下,其HBM3E的有源功耗低约30%(供应商发布的数据,方向性可信)。
美国生产。美光是唯一拥有美国晶圆厂的重要DRAM制造商。爱达荷州ID-1工厂于2025年10月开业;纽约Clay巨型晶圆厂提前至2027年。61亿美元的CHIPS法案拨款和75亿美元的贷款为数十年的资本支出下限提供了支持,这是任何亚洲竞争对手都没有的。
展望未来:自2025年第四季度起,HBM3E 12-Hi已向B300出货。HBM4于2026年第二季度向英伟达提供样品,2027年上半年量产——大致与三星持平,落后SK海力士约6个月。HBM已从两年前占美光收入不到2%上升到今天的约26%——比任何竞争对手经历的混合转型都要快。
为什么没有更多参与者?
2024年新建DRAM晶圆厂成本:150-250亿美元。交付周期:4-5年。良率爬坡:18-36个月。HBM特定封装资本支出(TSV、CoWoS等效):每个节点再增加20-50亿美元。
以实质性规模(10%份额)进入HBM市场所需的累计总资本支出:约300-500亿美元。所需时间:7-10年。
没有新进入者是可行的。中国厂商(长鑫存储、长江存储)落后3-5个节点,并且结构性受阻无法获得EUV。印度、日本和台湾的厂商都处于早期阶段。三巨头格局至少在未来十年内是稳固的。
结构性观察
非投资建议。需要跟踪周期中的五件事:
- SK海力士的HBM4领先地位是内存历史上利润率最高的产品。关注英伟达集中度(占收入的42%)和超大规模企业的双源采购——已在AMD MI400(三星)和Trainium 3(美光+三星)上可见。
- 三星的复苏有数据支持,而非猜测。1cnm良率收敛、HBM3E 12-Hi认证以及MI400的胜利终结了“结构性落后”的论点。悬而未决的问题:在HBM4E时代,代工厂加内存的整合是否重要?
- 美光已从可选性过渡到基本面。2026年HVM产能已完全预订,市场份额24%,CHIPS法案提供利润下限。主要风险是HBM4进度延迟。
- 台积电是沉默的第四参与者。尽管产能扩张了约3倍,CoWoS-L到2027年已售罄。内存和逻辑护城河现在在最先进的节点上耦合。

- 设备供应商捕获成比例的利润。每晶圆HBM资本支出强度是之前DRAM周期的3-5倍——流向光刻、TSV刻蚀、沉积和混合键合工具。
初创公司试图突破的领域
一波初创公司要么试图绕过HBM,要么在其之上构建新的抽象层。三个类别很重要。
- 内存处理单元(MPU)。计算被放置在内存阵列内部,因此数据永远不必跨越封装。架构赌注:随着数据移动主导能耗和延迟,芯片的重心将转向内存,计算成为卫星。几家早期初创公司已经在这个概念上测试了工作硅片,但该类别仍处于商业化前阶段——作为行业可能走向的前瞻指标有用,但尚未对HBM构成商业威胁。
- 定制HBM加SRAM加速器。特定于Transformer的ASIC,结合了用于容量的HBM和用于带宽的超大尺寸片上SRAM。Cerebras WSE-3拥有44 GB片上SRAM,聚合带宽为21 PB/s——完全没有HBM。Groq的LPU更进一步,每芯片约230 MB SRAM,并在数百个芯片上静态调度权重。MatX将HBM3E/HBM4与大型片上缓存配对,押注于工作负载专业化可以在每Token成本上击败英伟达的通用硅片。
- 内存结构。围绕内存的连接组织,而非内存本身。Astera Labs(CXL交换机和内存扩展器,现已上市)引领商业浪潮。Eliyan的NuLink提供有机基板芯片间互连,与硅中介层竞争——可能缓解台积电CoWoS的瓶颈。Enfabrica正在构建一个融合的网络和内存结构,可在机架内池化HBM和DDR。Celestial AI正在推动光子互连,声称内存和计算之间的每比特能耗降低10-100倍。
这些都没有取代HBM作为瓶颈的地位。每一个要么接受HBM作为基础并围绕它提取更多性能,要么在足够狭窄以至于SRAM可以替代的工作负载中绕过HBM。这正是三巨头格局保持稳固的原因。
内存三巨头是AI服务器中最集中、最资本密集型、最昂贵的瓶颈。HBM现在占加速器BOM的50%以上。每代英伟达产品内存带宽增长约2倍,而计算能力增长5-10倍。差距在扩大。三巨头捕获了利润。
几乎每一种架构响应——HBM4逻辑基础芯片、堆叠SRAM、PIM、MPU、CXL结构——最终都强化了同一个瓶颈。由英伟达和台积电驱动的未来十年AI资本支出,流入内存三巨头的部分将超过堆栈中的任何其他层。
瓶颈就是护城河。





